AI generates infinite subjects.
It repeats the same structure.
Structural diagnostics for generative systems. Image models and LLMs.
The Visual Thinking Lens measures what CLIP, FID, and human review pipelines miss: the spatial geometry generative models repeatedly produce.
Text-to-image systems generate endless semantic variation: people, city streets, animals, objects… but place them within highly constrained geometric patterns under standard prompting conditions. Semantic diversity explains less than 10% of observed spatial variance.
Composition is not prompt-driven. It is prior model-driven. In our studies spatial prompt intensity can explain as little as 0–0.1% of compositional displacement variance in text-to-image generation.

Current benchmarks measure if the butterfly looks like a butterfly.
This diagnoses regression, structural drift, and release stability.

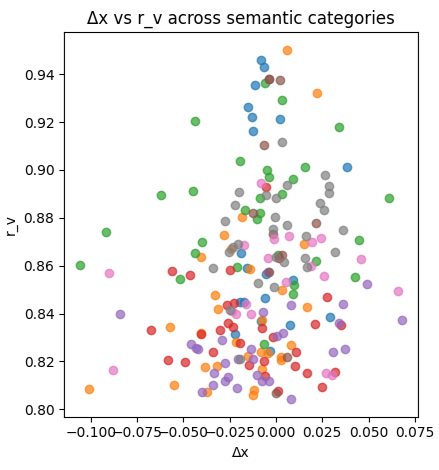
400 MidJourney prompts. 8 semantic categories. One geometric attractor.
Only 34% of horizontal space used (central attractor is only Δx = 0.005 ± 0.044)
100% of outputs within 0.15 radius of center
Semantic categories explain 6% of spatial variance
Different prompts, same pattern across engines, identical compositional bias. VTL measures the signature each engine learned from its training data and the spatial prior it applies regardless of what you ask for.

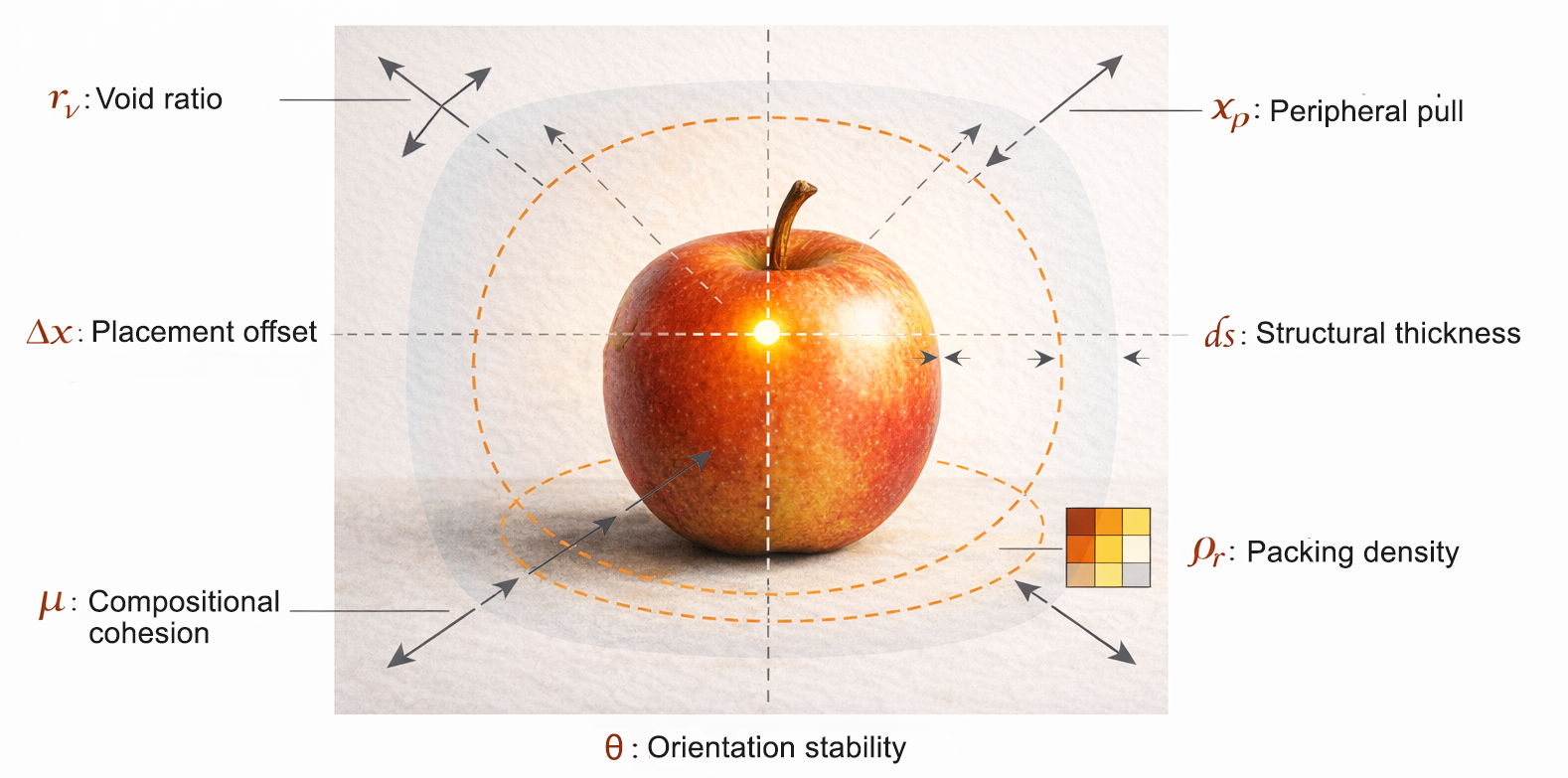
Our seven geometric primitives fingerprint any image:
Δx,y: Where mass sits (placement offset)
rᵥ: How much void surrounds it
ρᵣ: How compressed the marks are
μ: How unified the composition reads
xₚ: How hard the edges pull
θ: Orientation stability
ds: Structural thickness / surface depth
Run through our quick analysis tool, download the python or reach out for the multi-engine, recursive critique field, then apply structural intelligence to prompts, compositions, and symbolic logic. It (re)builds imagery in the ways defaults cannot see. Stable, reproducible and invisible to semantic evaluation.
Measuring compositional bias and structural behavior across all major platforms.
The Visual Thinking Lens Breaks the Pattern
A structural engine where making, breaking, and seeing are one recursive act.
These images span subjects, styles, and engines. All push against the geometric default into authorship. Try the Demo.










































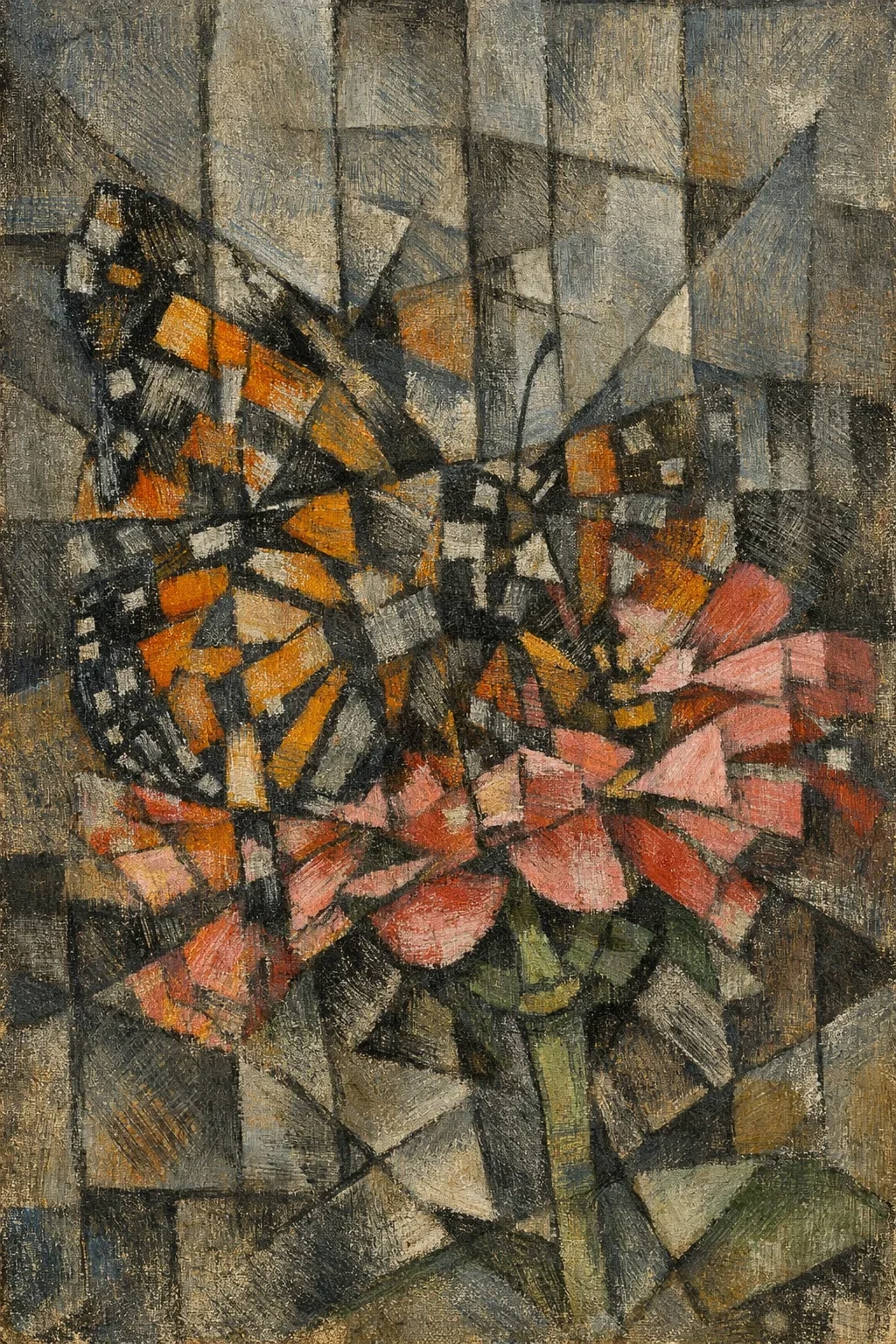






























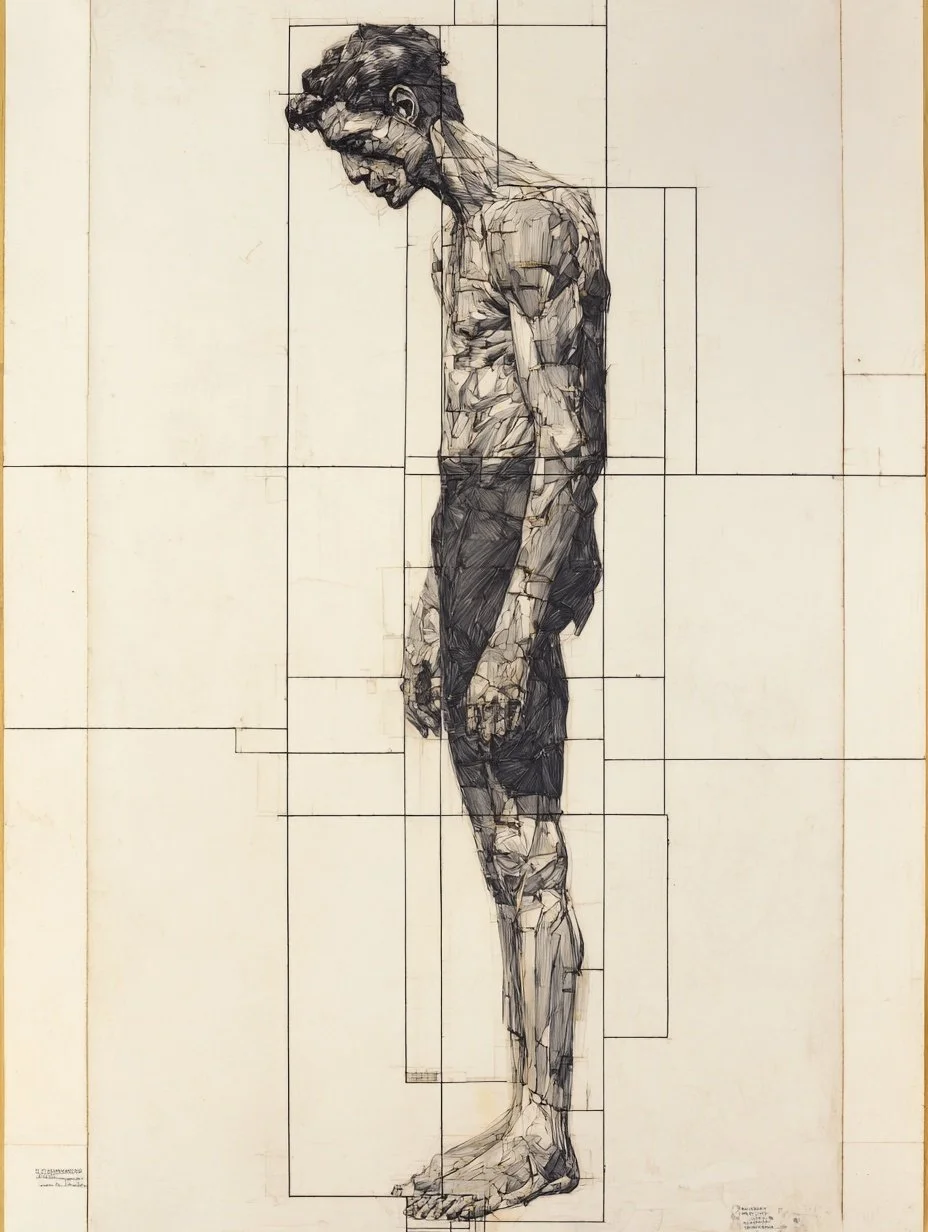
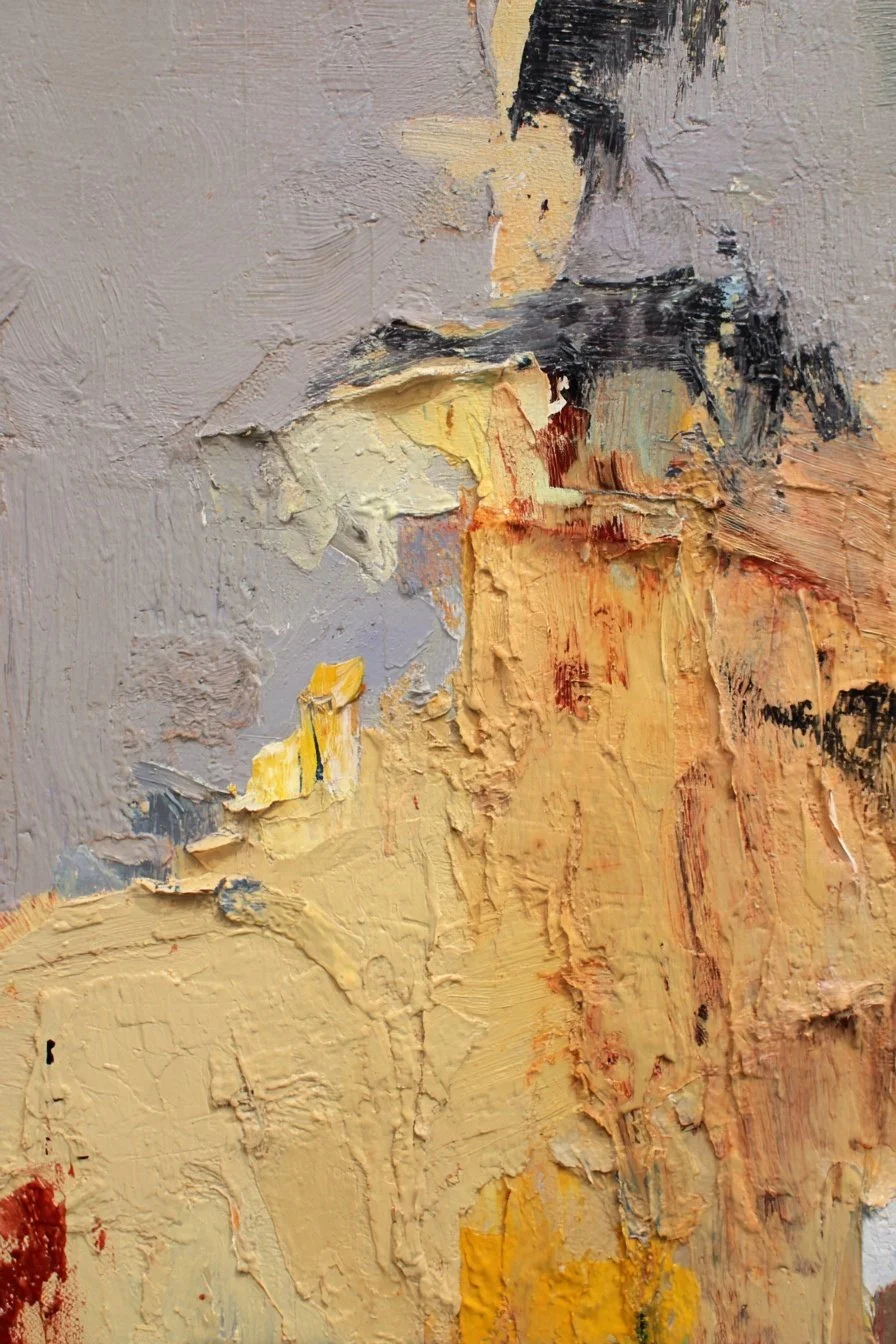
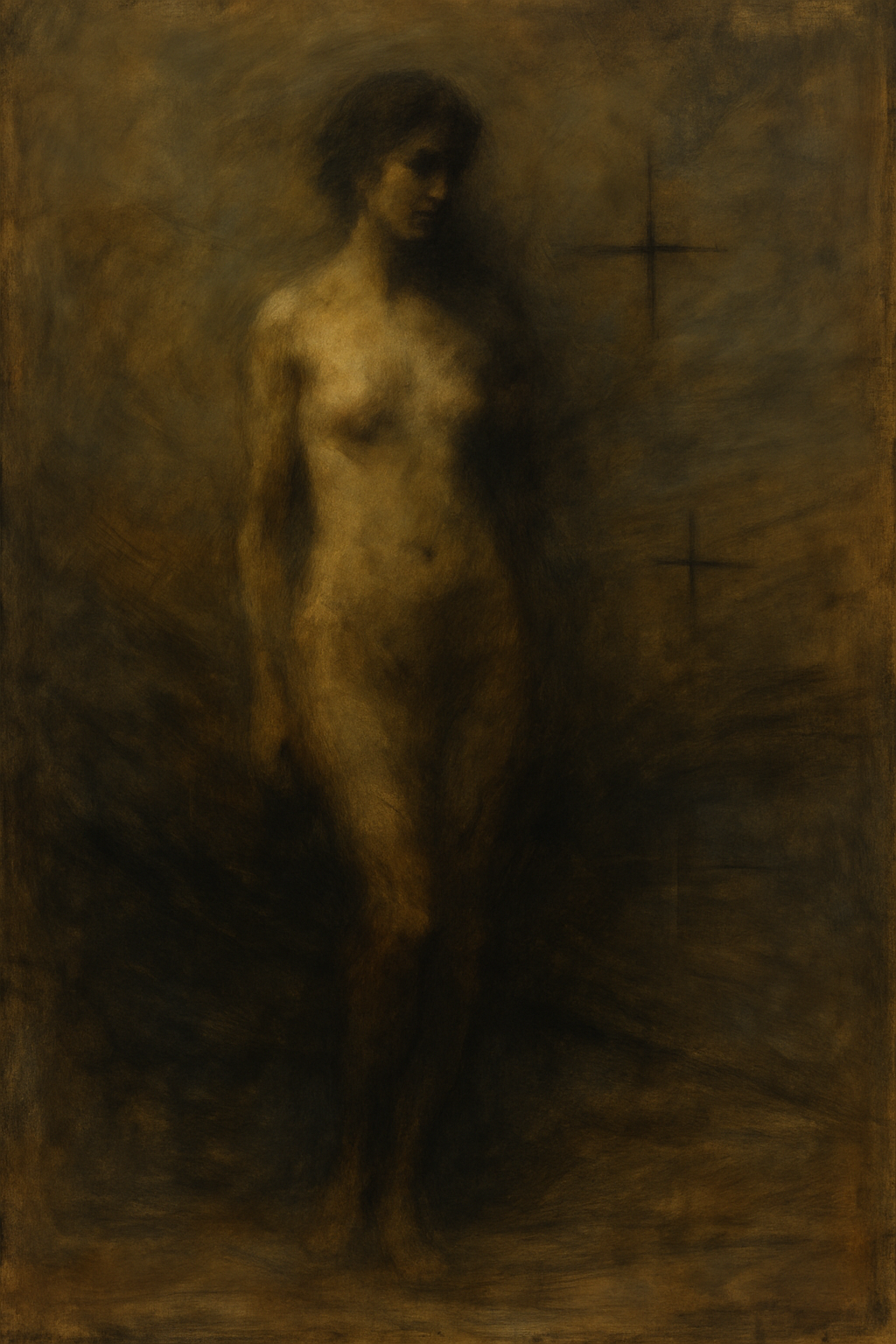









































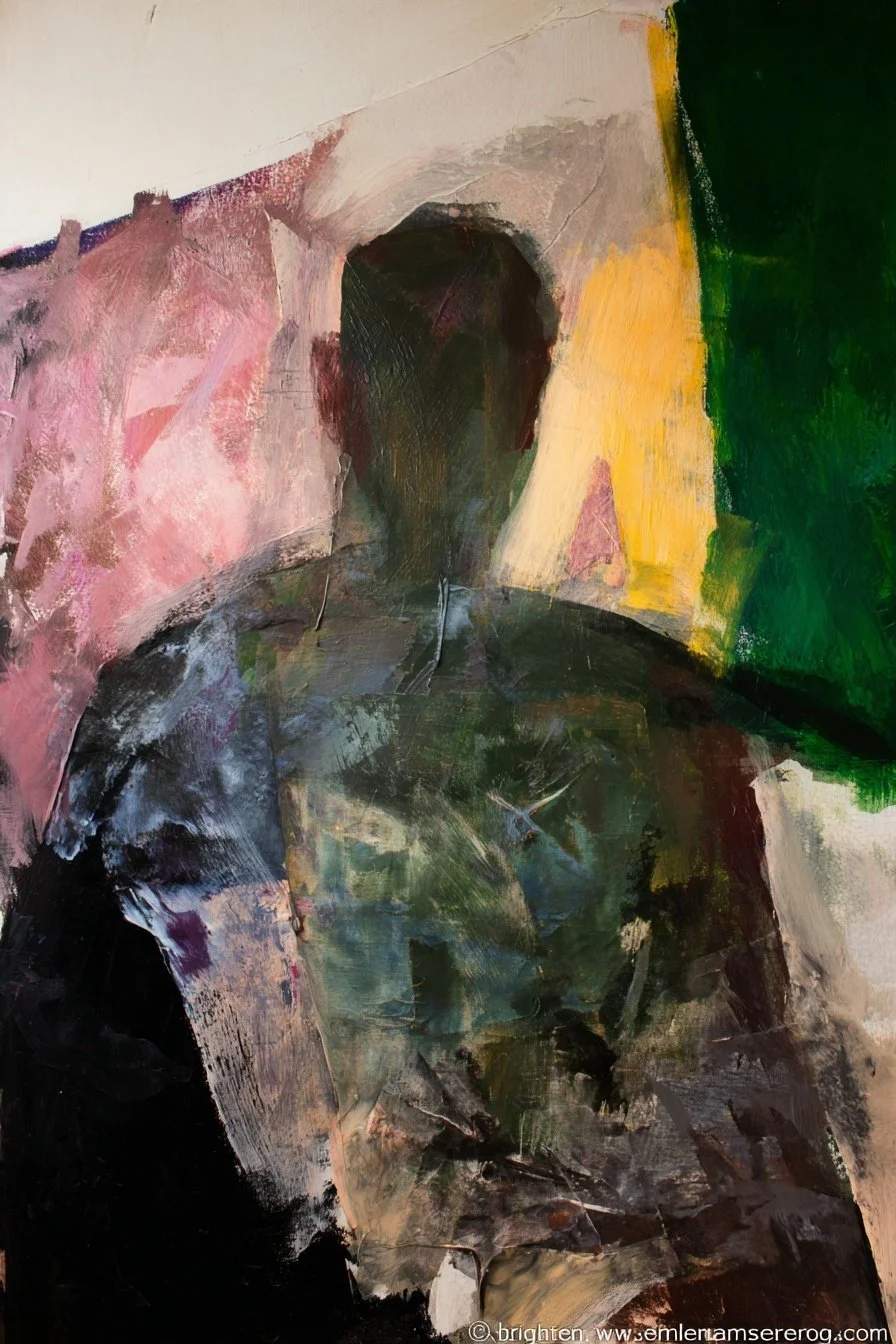































The Kernel becomes coordinates AI uses to organize space. They measure because they're stable, reproducible, and invisible to semantic evaluation. When applied back into AI, it gains spatial reasoning.
View our Library of before and after.
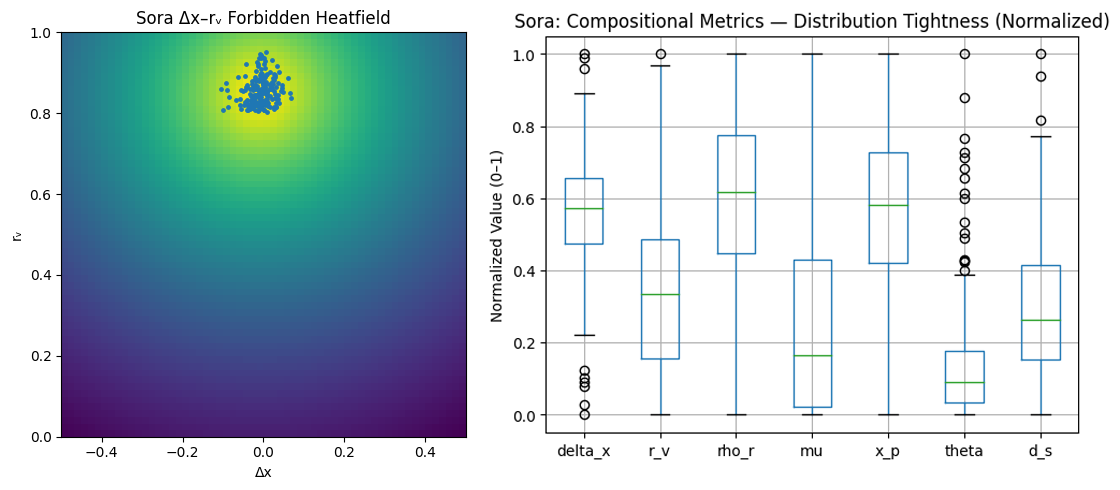
Where AI Won't Go: Evidence from 200 Sora Prompts
These aren't failures of capability. They're learned constraints. AI models have discovered that certain compositional coordinates reliably fail human evaluation, so they've learned to avoid them, even when you explicitly request them - but that doesn’t mean you have to.
Example: Extreme edge crops (Δx > 0.52) + high void = systematic refusal

Stable Territories in Compositional Space
Through systematic perturbation testing, the Lens can steer toward constraint regions where AI maintains compositional integrity under stress. These aren't aesthetic styles. They're geometric regimes that resist AI's pull toward center.
Artist basins are stable territories where AI maintains compositional integrity under constraint, but often need steered to. The off-center third or the peripheral anchor or compressed mass. AI has them in latent space, we providesthe coordinates to navigate toward them.
The VTL couples a generative-physics model (how images behave as mass in a field) with a multi-engine critique OS (how different analytic voices transform or interrogate that mass) to steer. The frog has the same semantic prompt, but different geometric instruction, moving from center to steered = 0.28, basin-navigated, vs cropped.

What else can the Kernel do? Soft Collapse Shows in Structure First
This is a deterministic structural regression layer that monitors compositional stability across model releases and fine-tuning updates. Model degradation appears in compositional metrics 3-4 inference steps before semantic breakdown. Within the kernel, Δx drift, void compression and peripheral dissolution all signal trouble while the image still looks fine to other metrics.
The kernel detects degradation, which matters for training evaluation, A/B testing, and quality monitoring at scale.
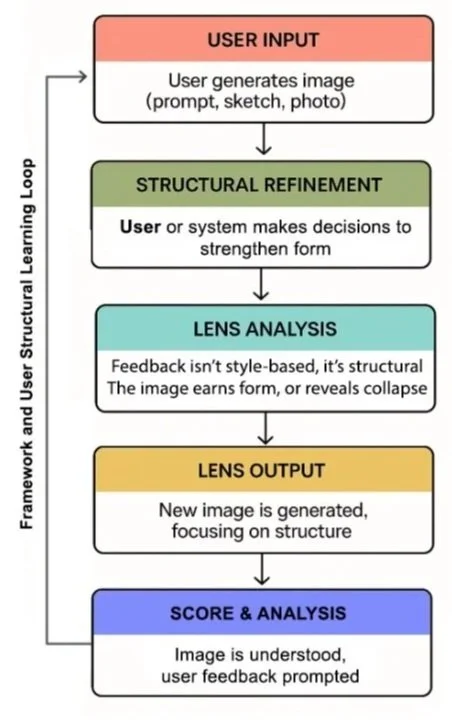
What the Lens does with an image.
The Lens isn't just diagnostic. It converts generative output into measurable structure:
Fingerprinting: stable and repeatable metrics
Steering toward specific compositional territories
Detecting: change under perturbation and pre-failure degradation
Controllability measurement: architectural differences through geometric signatures
Drift monitoring: Identifies “snap-back” or collapse behavior
Consistency: compare models or releases against a baseline
Consumer tools chase style. Research metrics chase numbers. The Lens chases spatial reasoning.
This is not about beauty or style
This is not a prompt framework
This is not subjective taste scoring
This is structural diagnostics for generative systems

The Lens is portable, reproducible, and engine-agnostic.
The Lens runs in top-tier conversational AI (Claude, GPT, Gemini) for measurement and steering. Python code offers drift free bench marks.
The logic is portable. The output can be research or discovery.
What works everywhere:
Cross-model fingerprinting (Sora, MidJourney, GPT, SDXL, Firefly, OpenArt)
Deterministic geometric measurement, no aesthetic judgment, no black-box scoring
Reproducible analysis via Jupyter notebooks or conversational AI
Core capabilities:
Image Fingerprinting - Compare engines by compositional signatures
Predictive Steering - Treat prompts as forces in geometric space, estimate drift and snap-back, try to push past it
Cross-Domain Analysis - Map visual geometry to rhetorical stance and narrative tension
Training Archaeology - Reverse-engineer learned priors from attractor behavior)
Models arrange space before they arrange meaning. VTL exposes the geometry priors before a model interprets meaning.

Built for artists, engineers, and researchers.
Researchers: A deterministic post-generation instrumentation layer that flags structural instability and behavioral regression in generative systems.
Product Teams: Quality monitoring at scale. A lightweight structural fingerprinting system for monitoring behavioral consistency in generative production pipelines.
Creative tools: A structural controllability diagnostic that measures whether user edits actually reshape composition or collapse back to default priors.
New to VTL? Begin here:
Mass, Not Subject - Foundational concept (15 min)
Kernel Primitives - Core measurements (10 min)
Monoculture in MidJourney - Empirical evidence (20 min)
Want practical application?
Deformation Operator Playbook - Hands-on techniques
The Off-Center Prior- Basin navigation
Foreshortening Recipe Book - Constraint architecture
Researcher or engineer?
Generative Field Framework - Technical spec
VCLI-G Documentation - Measurement methodology
GitHub link - Reproducible implementations
If you still believe prompts control composition, complete research package available.