Text Has Shape.
Measure it.
The Linguistic Kernel is a LLM behavioral telemetry system. An observability tool that is a behavior-only instrumentation layer for large language model outputs. It reduces any text string to a reproducible coordinate in structural space, without calling another model, without semantic judgment, without guesswork.
It measures how a response is structured, not whether that response is correct, persuasive, safe, or well-reasoned. The goal is to treat text as a measurable field so that models, prompts, and multi-turn workflows can be compared using auditable, reproducible signals rather than subjective evaluation or another model's judgment.
It will give you a reproducible fingerprint for any text output, a way to establish the shape of text for a given text, model, or prompt family, and a way to quantify how far and in what direction outputs move under different conditions. It’s deterministic and local. You can run it on every single token without the latency or cost of calling a "Judge LLM.”
THE PROBLEM
Two Broken Answers.
One Missing Instrument.
Most evaluation frameworks for language models fall into two categories and both have fundamental problems. This is a lightweight telemetry layer that detects structural anomalies in LLM outputs using text statistics.
PROBLEM 1
Benchmark Performance
Tells you how a model behaves on curated test sets under controlled conditions. Tells you nothing about structural behavior under production pressure, across conversation turns, or when output constraints are stressed.
PROBLEM 2
Early Warning System
Companies use vibes to monitor agents. The Kernel provides real-time structural telemetry. If your model’s Void Ratio spikes, your agent is about to fail, see it in your dashboard before your customer does.
PROBLEM 3
Model Drift
Define your Structural DNA. Lock your model into a specific Basin (B0-B3). If a model update pushes your outputs outside of your 'R95' safety radius, the Kernel triggers an automatic rollback.
PROBLEM 4
LLM-as-Judge
Introduces the circularity it is meant to avoid. You are using a stochastic, non-deterministic system to evaluate another stochastic system. The judge has its own structural biases, its own failure modes, its own drift.
Most production failures are not benchmark failures. They are structural reliability failures, invisible to content-level evaluation, measurable with the right instrument.
The Linguistic Kernel is:
Deterministic
The same input always produces the same output. No model in the loop. No stochastic components. Every number is backed by countable evidence features.
Auditable
Every coordinate has a countable source. The evidence bundle exposes all raw features that drove the computation. Nothing is hidden in a neural network's judgment.
Engine-Agnostic
Measures only what is visible in the produced text. Works identically on GPT, Claude, Gemini, or any open-weight model. No model-specific calibration required.
THE COORDINATE SPACE
Eight Dimensions.
One Structural Fingerprint.
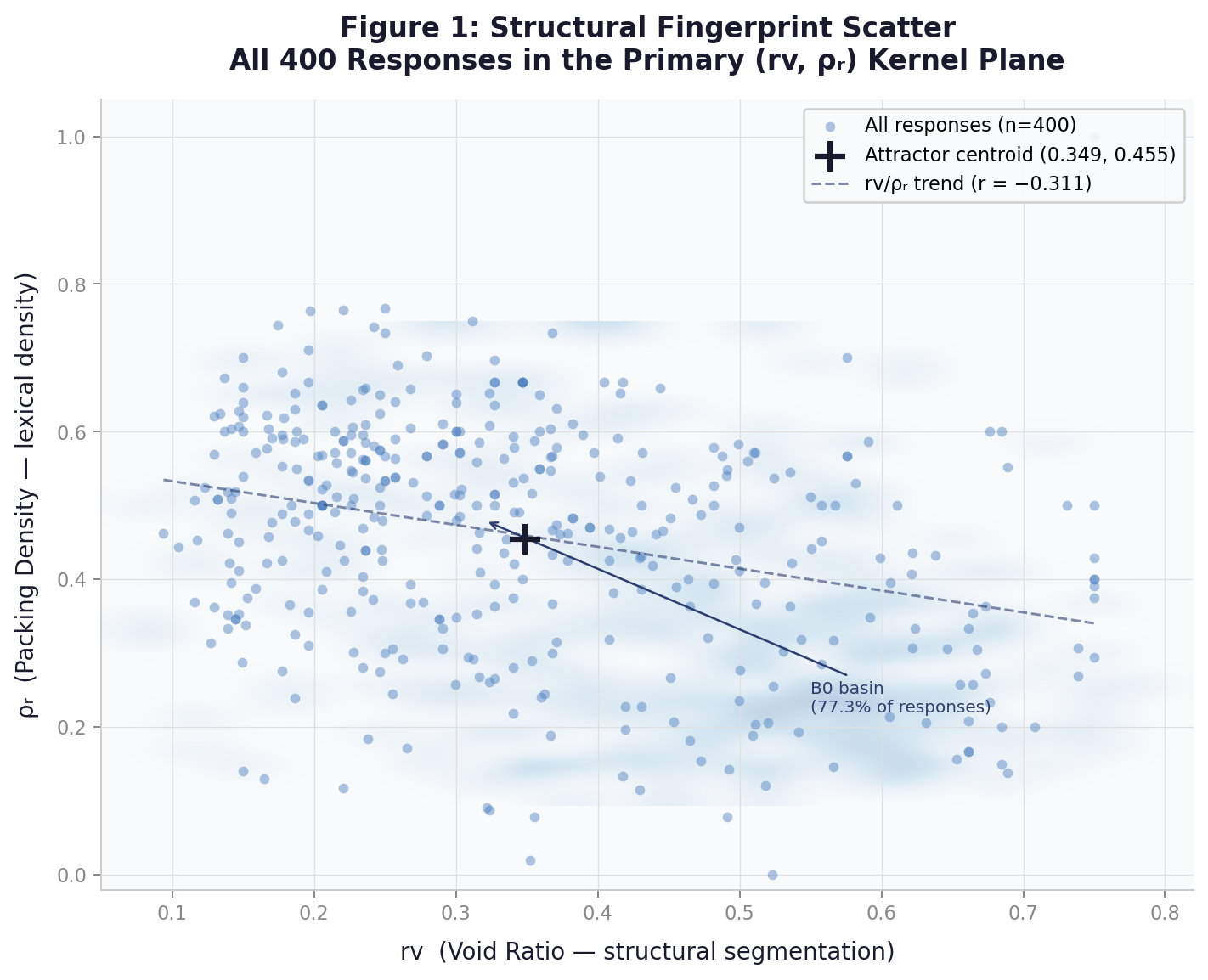
The kernel reduces any text to a point in an eight-dimensional structural space. The first four are the canonical core. The second four are auxiliary. Each dimension captures something orthogonal — no two measure the same thing. Everyone else is trying to be the "Critic." This tool is the "Ruler." Monitor and observe token compression, segmentation collapse, truncated responses and safety pipelines. Monitor the health of an LLM system by watching how the structure of its outputs changes over time.
CORE KERNEL — K = [Δx, rᵥ, ρᵣ μ]
Δx
WEIGHT SHIFT
Where informational mass lands across the response. Front-loaded vs. back-loaded vs. centered. Computed as a weighted centroid over sentence position.
rᵥVOID RATIO
Structural air and breathing room. Captures paragraph density, bullet structure, short-sentence proportion, and average sentence length in a single composite.
ρᵣ
PACKING DENSITY
Concentration of content-bearing tokens relative to connective language. High values mean lexically dense, information-packed delivery. Low values mean connective tissue dominates.
μ
COHESION
Continuity of discourse scaffolding. Counts transition markers and reference pronouns that stitch sentences together. High cohesion means explicitly linked structure.
AUXILIARY SET — AUX = [Δy, Xₚ, Θ, Dₛ]
Δy
SEGMENTATION STRAIN
Average sentence length relative to a 15-token neutral baseline. Tracks punctuation suppression, verbosity constraints, sentence boundary collapse.
xₚ
PERIPHERAL PULL
Edge-seeking behavior. Measures word rarity against a 6,355-word common-English baseline (Zipf-grounded). Domain-agnostic: jargon in any field scores high.
θ
FLOW INSTABILITY
Non-linear jumps between adjacent sentences. One minus mean cosine similarity between neighboring sentence token distributions. High values mean abrupt topic movement.
dₛ
STRUCTURAL THICKNESS
Clause stacking and subordination density. Counts true subordinating conjunctions and weighted punctuation markers per token. Measures sentence layering pressure.
THE PROCESSING PIPELINE
Five Stages.
No Model in the Loop.
Every kernel computation passes through a deterministic five-stage pipeline. No external service. No randomness. No hidden scoring model.
01: Tokenize & Segment: Text is split into words, sentences, and paragraph blocks. Bullet lines handled as structural units.
02 Extract Evidence: Count every feature: tokens, sentences, transitions, pronouns, subordinators, contrast markers, rare words, metaphors.
03: Compute Coordinates: Evidence features transform into the eight kernel dimensions via defined, versioned mathematical functions.
04: Classify: Basin assignment and rhetorical state derived from coordinates. Z-space normalization applied when a prompt-family baseline is fitted.
05: Assemble Output: Coordinate, basin, evidence bundle, rhetorical state, segmentation flag, and full versioning metadata returned as a structured dictionary.
From the kernel import
kernel = LinguisticKernel()
result = kernel.compute("Your LLM output goes here.")
# → kernel coordinate
result["kernel"] # {"Δx": 0.004, "rᵥ": 0.068, "ρᵣ": 0.676, "μ": 0.490}
# → auxiliary dimensions
result["aux"] # {"Δy": 0.85, "xₚ": 0.567, "θ": 0.880, "dₛ": 0.526}
# → rhetorical state and basin
result["basin"] # "B0_centered_compact"
result["evidence"]["rhetorical_state"] # "assertive"
# → every count that produced those numbers
result["evidence"] # full audit bundle
APPLICATIONS
What You Can
Build With It.
Because the kernel is deterministic and engine-agnostic, it composes into a range of operational and research applications. Quantify your voice. Monitor or turn your AI into a fixed coordinate.
01 ——
Production Monitoring
Establish a structural baseline for each major prompt family in your application. Instrument your inference pipeline to compute the kernel on sampled outputs. Alert on rising breach ratios — structural shifts often precede downstream failures.
03 ——
Steerability Studies
Apply controlled perturbations — constraint additions, polarity flips, length compressions — and measure coordinate deltas. Δy is the primary steerability axis for constraint-type prompts. Identify which prompts are structurally elastic and which are anchored.
02 ——
Engine Comparison
Run the same prompt family through multiple models. Compare centroids, R95 radii, and breach rates under identical stress conditions. Different engines have different structural fingerprints — make those differences measurable.
04 ——
Multi-Turn Drift Analysis
Track structural trajectory across conversation turns. Healthy conversations show moderate variation around baseline. Problematic ones show systematic drift with no recovery. Hysteresis measures whether the return path is symmetric with the departure path.
05 ——
Collapse Prediction
Structural collapse signatures — silence, refusal, constraint-induced degeneration — cluster in geometrically separable regions of kernel space. Elevated breach ratios are early warning signals detectable before content-level failure is visible.
06 ——
Red Team Infrastructure
Use the kernel as a structural excursion detector in adversarial testing. Prompts that push the model into unusual structural territory are visible as coordinate outliers before semantic evaluation identifies the problem.
VALIDATION
What the Corpus
Studies Showed.
Validated across models, conditions, and perturbation studies. Consistent results. Across Claude, GPT, and Gemini, more than 4000+ responses, multiple task types, and controlled perturbation families. Consistent results across everyday, math and science (EMS) prompt conditions, each with deliberate batch-load stress tests to expose structural behaviors that single-prompt evaluation misses. What holds across all runs:
Structural behavior clusters tightly around a consistent centroid for any given model under normal conditions. No random structural wandering. 89% of Gemini (EMS) responses fall within a single geometrically coherent attractor basin. The cross-engine study confirms this holds across all three architectures.
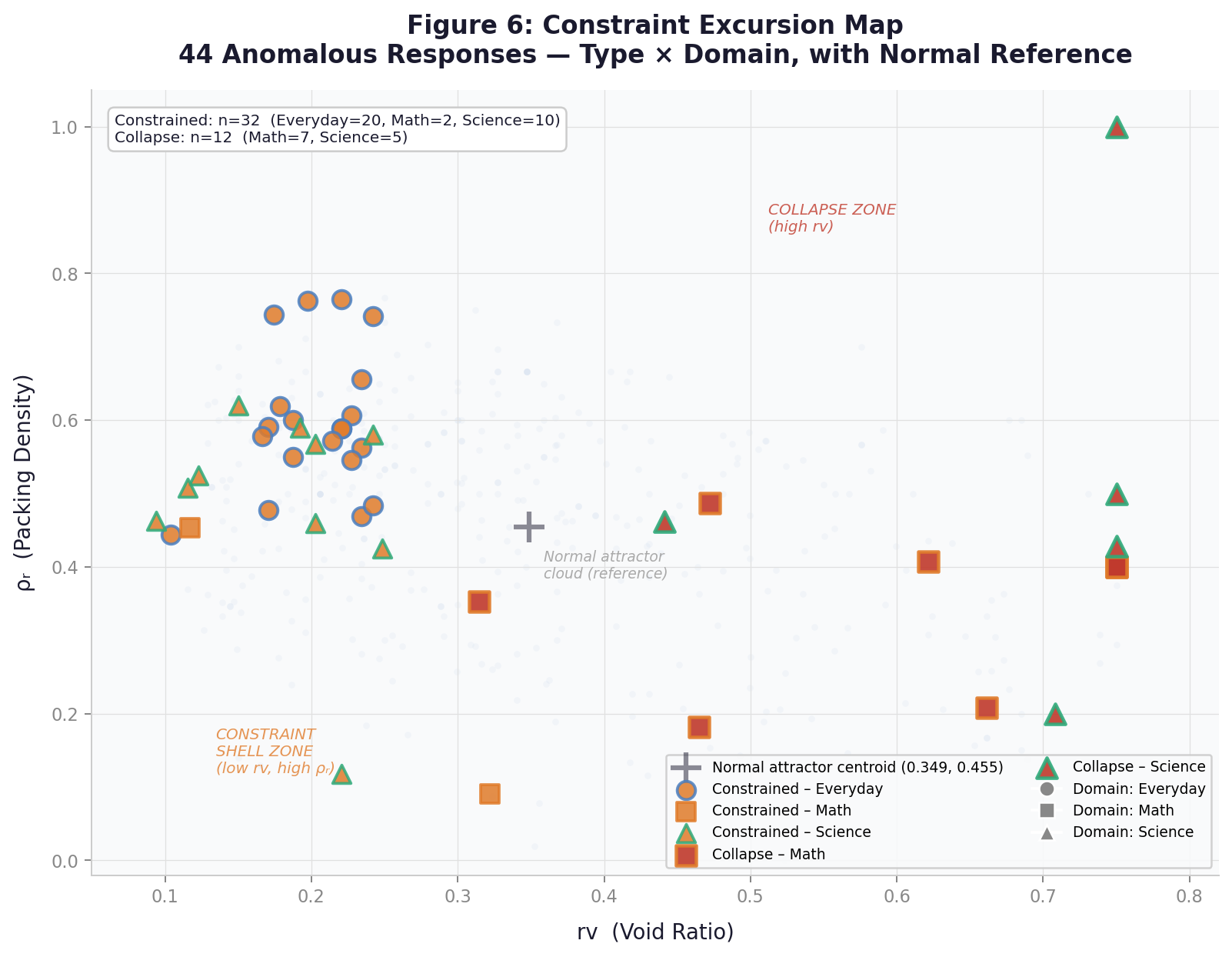
The two primary failure modes occupy geometrically opposite regions of kernel space and are separable without semantic evaluation. Formatting collapse inflates rᵥ and compresses Δy. Constraint compliance collapses rᵥ and spikes Δy to 1.67 (d=+2.54). A single detection threshold cannot catch both. Two observation windows are required.
Collapsed responses are displaced 1.63–1.97× farther from each engine's neutral centroid than normal responses. The geometry of failure is distinguishable before content-level errors are visible.
Certain prompt types produce cross-engine collapse regardless of model. Prompts requiring sustained multi-step LaTeX derivation — quantum mechanics, matrix algebra, normalization integrals — triggered formatting collapse in both Gemini and GPT in the batch study while Claude completed them without failure. The failure is a property of rendering demand under load, not model capability.
Domain is a structural predictor of collapse risk, and the risk profiles are approximately inverted across failure modes. Math prompts collapse at 10% (Gemini) and 5% (GPT) under batch load; Everyday prompts collapse at under 1.5%. Everyday prompts drive the highest constraint compliance rates.
Δy is the primary steerability axis for constraint-type prompts. Segmentation strain spikes under verbosity constraints and relieves under length compression. The Gemini single-engine study shows Δy Cohen's d of 2.47 between normal and constrained responses — the largest effect size observed across all eight dimensions in either corpus.
Cohesion (μ) is structurally invariant across engines, domains, and rhetorical states. In the cross-engine study, all pairwise comparisons across three engines and four output states are non-significant (all p > 0.14, CV 0.046–0.057). When μ moves, something more fundamental than formatting pressure has changed.
Structural fingerprints are engine-specific and measurable. Claude produces 2.1× more tokens per response than Gemini or GPT under identical batch conditions, expands output across batch positions rather than compressing, and shows significantly higher flow instability on Everyday prompts (θ d=−0.59 vs GPT). These are structural signatures, not quality rankings.
Case Study
Structural Telemetry for LLM Outputs Under Batch Load: A Cross-Engine EMS Study (1,200 responses spanning Claude, GPT and Gemini)
Structural Residue: Kernel Metrics as Surface Signatures of Generation-Level Uncertainty in LLM (syntactically complex text is harder to generate than it looks, and you can measure it from the finished text alone)
Structural Telemetry of Gemini Responses Under Batch Constraint (400 Gemini responses spanning Everyday, Math, and Science)
Proof of Concept Studies
Text Has Shape: Local Deformation Spectrum of a Language Model (1,600 Jacobian Mapping in Kernel Space)
Text Has Shape: Structural Operating Envelopes in Large Language Models (1,600 A Deterministic Kernel Approach to Output Geometry and Steerability
INSTRUMENT BOUNDARIES
What It Explicitly
Does Not Claim.
Understanding the limits of a measurement instrument is as important as understanding its capabilities.
Ground-truth correctnessA factually wrong response and a correct one can occupy identical kernel coordinates if they are structurally similar. The kernel is not a fact-checker.
Semantic meaning or content qualityTwo responses that say the same thing in different structures will have different coordinates. Two responses that say different things in similar structures will have similar coordinates. Orthogonal to semantics by design.
Intelligence as a single scalarThere is no total score. No ranking from good to bad. No summary number. The kernel produces a coordinate. What that coordinate means requires context.
Internal model mechanismsThe kernel is a black-box external instrument. It sees only what is in the output string. No access to attention patterns, activations, or internal representations.
All geometric language refers to induced structure in feature space only. This kernel is a structural deformation monitor for output stability, not a geometric model of language. No manifold claims. Just the text.