MidJourney can generate almost anything.
But beneath that surface variety, every composition resolves to the same skeleton: centered subject, 85% void, a quiet radial pull that keeps everything safe. This study measures that pattern.

Most evaluation metrics evaluate what appears in the image, but not how the model organizes space. The VTL kernel measures spatial reasoning, the internal geometry of the frame.
→ This is not a claim that MidJourney cannot produce varied compositions under authored prompting conditions, but that its default operational mode exhibits severe geometric compression regardless of semantic input.
The Illusion of Variety
We generated 400 images from 100 different prompts across multiple subject categories:
butterflies • businessmen • landscapes • underwater scenes • fractals • architecture • objects • abstractions
At first glance: enormous creativity.
When we measure composition priors instead of subject matter, the images collapse into the same skeletal structure.
Key findings:
Δx (placement offset): nearly perfect centering
rᵥ (void ratio): ~80–96% is below the 75th-85th percentile of gradient magnitude
This happens observably with high frequency.
Different subjects, same bones. A wide range of subjects. The spatial template barely changes.

How We Measured Composition
Instead of asking whether an image matches its text prompt, we asked: where is the visual mass, how much space does it leave, and how does it push the frame? We measured gradient fields: the edges and contrast patterns that carry visual weight. This shift from 'what objects are present' to 'how is visual weight distributed' enables model-agnostic, contrast-invariant, fully deterministic analysis of spatial structure.
The core insight is that composition is expressed in changes, not absolutes. An image's compositional forces emerge from edges, contrast boundaries, and texture gradients. These high-gradient regions define the visual mass of an image, not the semantic mass. A standing figure's compositional weight includes its silhouette, the shadow it casts, and tonal relationships with the background. What matters compositionally is where rapid change occurs, not what those changes represent. The centroid measured here is the mass centroid of the gradient field, not the semantic or object centroid.
The VTL kernel translates this into seven measurements:
Delta x: Horizontal displacement of gradient-weighted centroid from frame center
rv: Proportion of image occupying low-gradient regions (negative space)
rho_r: Local concentration of high-gradient pixels (detail density)
mu: Structural fragmentation versus unity, measured via connected component entropy
xp: Net directional force toward frame edges (peripheral pull)
theta: Alignment to vertical/horizontal axes versus omnidirectional scatter
ds: Volumetric solidity versus filamentary thinness (structural thickness)
Each metric captures a distinct compositional force. Together they map the geometric skeleton beneath the semantic surface.
The Compositional Fingerprint: 400 Images, n=100 Prompts
Table 1 summarizes the measured spatial structure across all outputs. The numbers are stark.
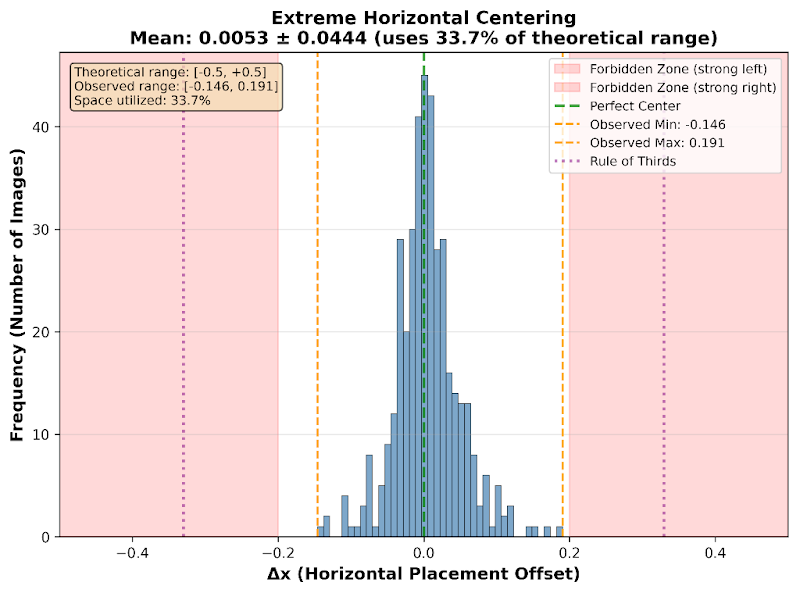
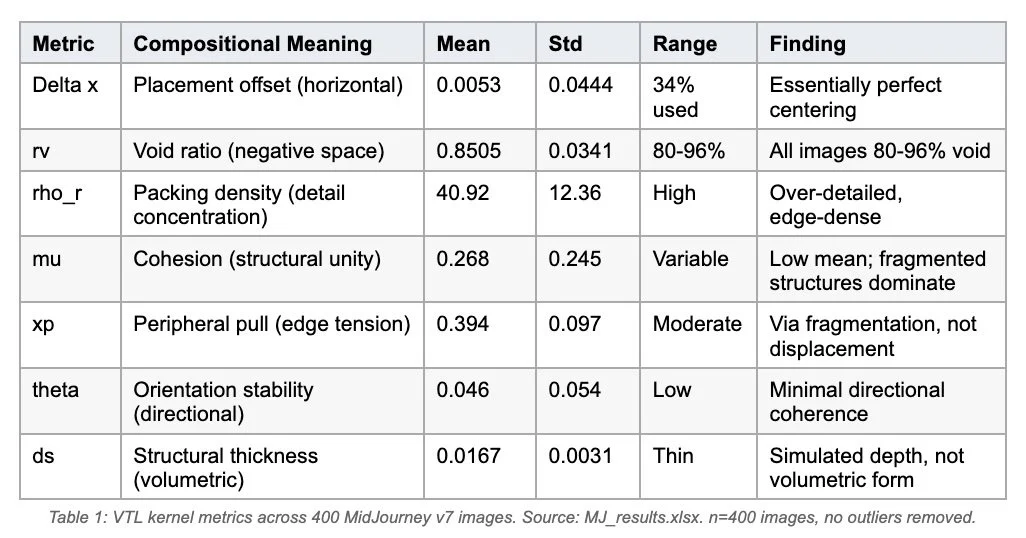
The horizontal placement variance is 0.0444, meaning the model uses only 34% of available horizontal compositional space. The most extreme leftward image sits at Delta x = -0.146; the most extreme rightward at Delta x = +0.191. Both are what any artist would still call 'centered.' The void ratio is more striking: 85% of every image, regardless of subject, consists of low-gradient regions. The model maintains this near-constant void across butterflies, businessmen, cathedrals, and fractals with a standard deviation of only 0.034.
One finding deserves particular attention: MidJourney achieves edge tension (xp = 0.394) through fragmentation (low mu) rather than through lateral displacement (Delta x). This explains the characteristic 'muddy edge' quality: compositional energy reaches the frame boundary through scattered detail, not through deliberate subject placement. The model creates the appearance of spatial tension without ever committing to asymmetry.
Forbidden Zones
When we plot all 400 images on a map of Delta x versus rv, the most revealing feature is not the cluster. It is the empty space around it. Entire regions of compositional space are systematically absent, not by chance, but by architectural constraint. These are the forbidden zones.
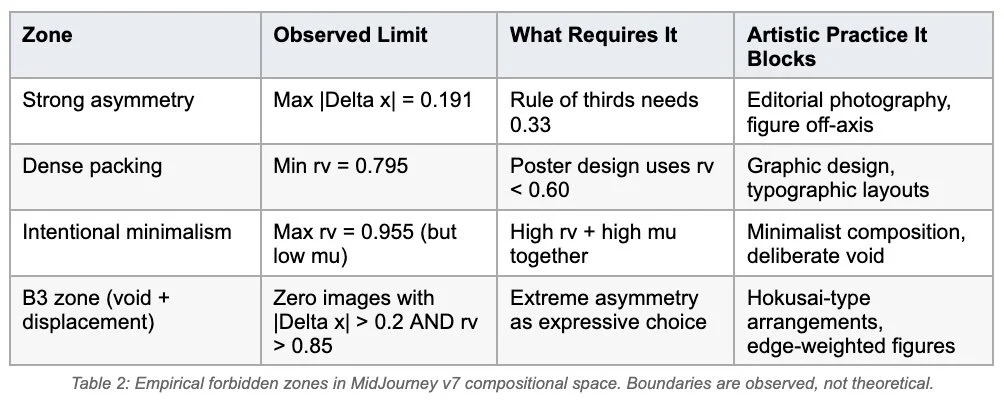
The practical implications for working artists are concrete. Prompting 'tiny figure in extreme lower-left corner, vast empty white wall' produces Delta x = -0.0181 (effectively centered) with rv = 0.9491 (standard void). The prompt is honored semantically: the figure is small, there is white wall. But the template persists. The counter-mass of the corner creates a centralized composition regardless of explicit instruction. These are not prompt engineering failures. They are architectural limits.
Canonical works across art history occupy coordinates MidJourney cannot reach. Caravaggio's The Calling of Saint Matthew, Degas's off-center ballet compositions, Hokusai's The Great Wave, and Vermeer's Woman Reading a Letter all employ radical asymmetry, extreme void allocation, and deliberate placement pressure at frame edges. These are not stylistic preferences; they are established compositional vocabulary, taught in every art school, available to every human artist, and inaccessible to MidJourney's default generation mode.
Radial Envelope
Across wildly different images, octopus arms, cathedrals, peacocks, butterflies, concentric kernel overlays reveal a shared underlying template: a radial envelope centered in the frame. The subject varies. The envelope does not.
This pattern suggests something about generation sequence. Compositional structure likely stabilizes early in the diffusion process, establishing the spatial prior before semantic details arrive. Prompts influence content; they do not override structure. The skeleton forms first, and semantics fill in around it. What looks like a compositional choice is the absence of one.
Four compositional modes exist within this envelope, identified by cluster analysis across the 400 images:
C0 (9.5%): Neutral Default. Centered, high void, fragmented. No strong compositional strategy. Activated when semantics do not trigger a specific prior.
C1 (23.0%): Dense Cohesive. Lower void, high density, high cohesion. Subject-forward rendering. Triggered by organic forms, portraits, and products.
C2 (37.8%): Structured General. Near global mean on all metrics. Balanced, proficient, unremarkable. The most common mode across diverse subjects.
C3 (29.8%): Void-Heavy Fragmented. Highest void, lowest density, extreme fragmentation. Scenic and fractal aesthetic. Triggered by architecture, landscapes, and abstractions.
All four clusters share the same foundation: Delta x within [-0.02, +0.02] and rv within [0.82, 0.89]. Different flavors, same foundation. Four modes occupy one narrow region of compositional space. Semantic diversity runs to 100 categories. Compositional diversity produces four modes, all within Basin B0.

Consequence
For Artists and Designers
These tools promise infinite creative possibility. What they deliver is infinite semantic variety organized within a single compositional template. Over time, this normalizes a narrow idea of what good composition looks like, and it does so invisibly, because the semantic surface changes while the structural substrate does not. A generation pipeline that always centers, always maintains 85% void, and always resolves tension through fragmentation rather than placement is not a compositional tool. It is a semantic tool with a fixed compositional default.
The professional applications most dependent on compositional precision are precisely the ones current models cannot serve reliably. Editorial layouts require predictable negative space for text placement. Product photography follows grid systems and visual hierarchies. Architectural visualization depends on asymmetric viewpoints that convey scale. Data visualization requires precise subject placement to communicate quantitative relationships. For all of these, current models offer semantic control ('show me a product') without compositional control ('place it at 0.3 horizontal offset with void on the right'). The result is endless regeneration hoping for a compositional accident.
For Evaluation and Research
CLIP scores confirm that these 400 images accurately match their text prompts. FID scores indicate photorealistic quality. Human evaluators rate them as aesthetically pleasing. None of these metrics detect the monoculture. A model can score excellent on every standard benchmark while exploring only a narrow corner of compositional space. The evaluation ecosystem is measuring semantic accuracy and distributional similarity. It is not measuring geometric behavior.
The semantic question 'is this a good butterfly?' is answered by existing metrics. The geometric question 'where is the butterfly, and why is it always in the same place?' goes unasked. This is not a gap at the margins. It is a gap at the center of what generative models are actually doing.
For Engineering Direction
Compositional structure should be treated as its own domain of control and testing, not as a side effect of semantic generation. The right questions for model development are: where does the model refuse to go, even when asked? What prompting strategies actually shift spatial priors versus shifting semantic content while preserving geometric defaults? How does architectural intervention, not just prompt intervention, change the shape of accessible compositional space?
The blank regions in the Delta x-rv scatter plot are not noise. They are evidence of architectural constraint. Measuring them is the first step toward changing them.

Takeaway
This is not an argument that MidJourney produces bad images. It does not. It is a structural observation: semantic diversity is enormous; compositional diversity is not. The model has learned to generate infinite semantic variations of a single compositional template. That is a fundamentally different achievement than true visual flexibility, and current evaluation infrastructure cannot see the difference.
If we want generative systems that expand visual possibility rather than normalize a narrow default, we need to measure and challenge the invisible spatial priors they obey. The VTL kernel framework provides the methodology. What it reveals, with 400 images and 100 prompts as evidence, is a model operating inside a tight envelope it never acknowledges and current benchmarks never interrogate.
Monoculture is not failure. Prompt steering is possible. This is not framed as a flaw. It is a measurable pattern, one that likely emerges from optimization pressures, dataset biases, and stability preferences. The question is not whether MidJourney is broken. The question is whether we can see what it is doing. Now we can.
This work combines measurement infrastructure, operational methods, and mechanistic hypotheses. Numerical results are reproducible facts; frameworks are interpretive constructs; mechanistic explanations are evidence-based inference from observed behavior, not claims about model architecture.
(c) 2025 Russell Parrish / A.rtist I.nfluencer. All rights reserved. No part of this system, visual material, or accompanying documents may be reproduced, distributed, or transmitted in any form or by any means, including AI training datasets, without explicit written permission from the creator.
