Same prompt. Four engines.
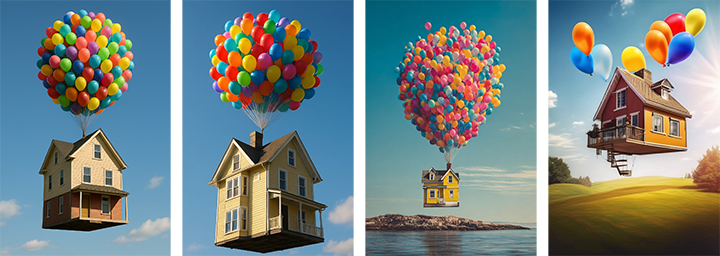
Each one made structural decisions on your behalf.
Generative models arrange visual mass predictably, even when prompts ask them not to. Their spatial decisions follow stable inductive biases that remain invisible to benchmarks.
The VTL measures those spatial priors without accessing training data and recursively rebuilds.

Every image has geomety.
Until we measure it, we can’t steer it.
Modern vision-language benchmarks measure semantic correctness, whether a model correctly depicts "a mouse" or "a chair." They cannot measure structural failure: unstable geometry, void collapse, predictable spatial priors.
This mouse is not semantic failure. This is structural failure. Both Sora images depict the subject correctly. Captioning would pass, semantics are intact, but only one image is stable.
One image: coherent field geometry, stable perspective, consistent ground plane
Other image: perspective distortion, void pull, vanishing-field instability, structural breakdown
Both pass semantic evaluation (CLIP, GenEval, captioning tests). Only one is structurally coherent.
Current metrics measure what the model describes. VTL measures how the spatial field holds together using geometry-based field metrics.

The coordinate Syst:
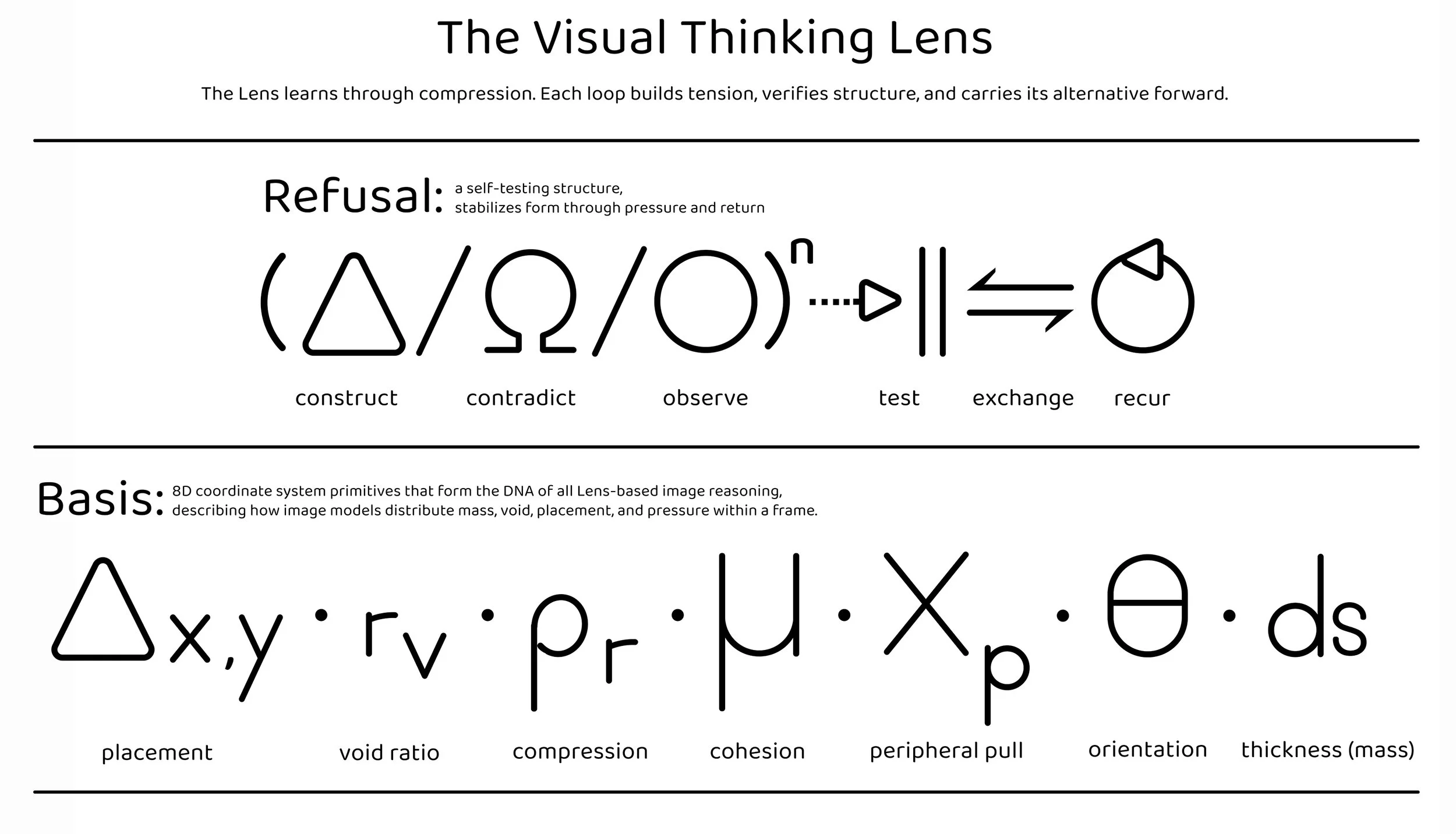
Seven Geometric Primitives
VTL quantifies compositional structure through seven measurements per image to break free from a platform’s built in culture of monoculture:
Core Primitives:
Δx,y — Placement offset (centroid distance from frame center)
rᵥ — Void ratio (gradient and texture)
ρᵣ — Packing density (material compression / mass adjacency)
μ — Cohesion (structural continuity between marks or regions)
xₚ — Peripheral pull (force exerted toward/away from frame boundaries)
θ — Orientation stability (gravity alignment, architectural/figurative compositions)
ds — Structural thickness (layering, mark-weight, material permeability)
These primitives form coordinate systems. Not aesthetic judgments. Not style preferences. Geometric measurements of how AI distributes mass, void, and pressure within a frame.
Generative models arrange visual mass predictably, even when prompts ask them not to.
This framework: scores, critiques and steers prompts through semantically aware constraint logic to form compositional alternatives.
Give it an image. Select a movement. Watch it rebuild.

The Recursive Forumla:
(Δ/Ω/O)ⁿ ⇢ || ⇋ ⥀
A five-part recursive architecture uses the kernels for reasoning and structural critique:
Δ (Delta) — Transform/construct: Compositional evolution, adaptive change
Ω (Omega) — Rupture/refusal: Contradiction, fracture, symbolic defiance
O (Circle) — Observe/stabilize: Measures what remains after change
System Routing:
|| (Axis Logic) — Tests integrity before recursion, structural validation
⇋ (Bidirectional Exchange) — Interpretation meets generation, conversational loop
⥀ (Recursion) — Image altered, re-enters as new form of understanding
The Loop: Prompt → Image → Critique → Revision → Image²
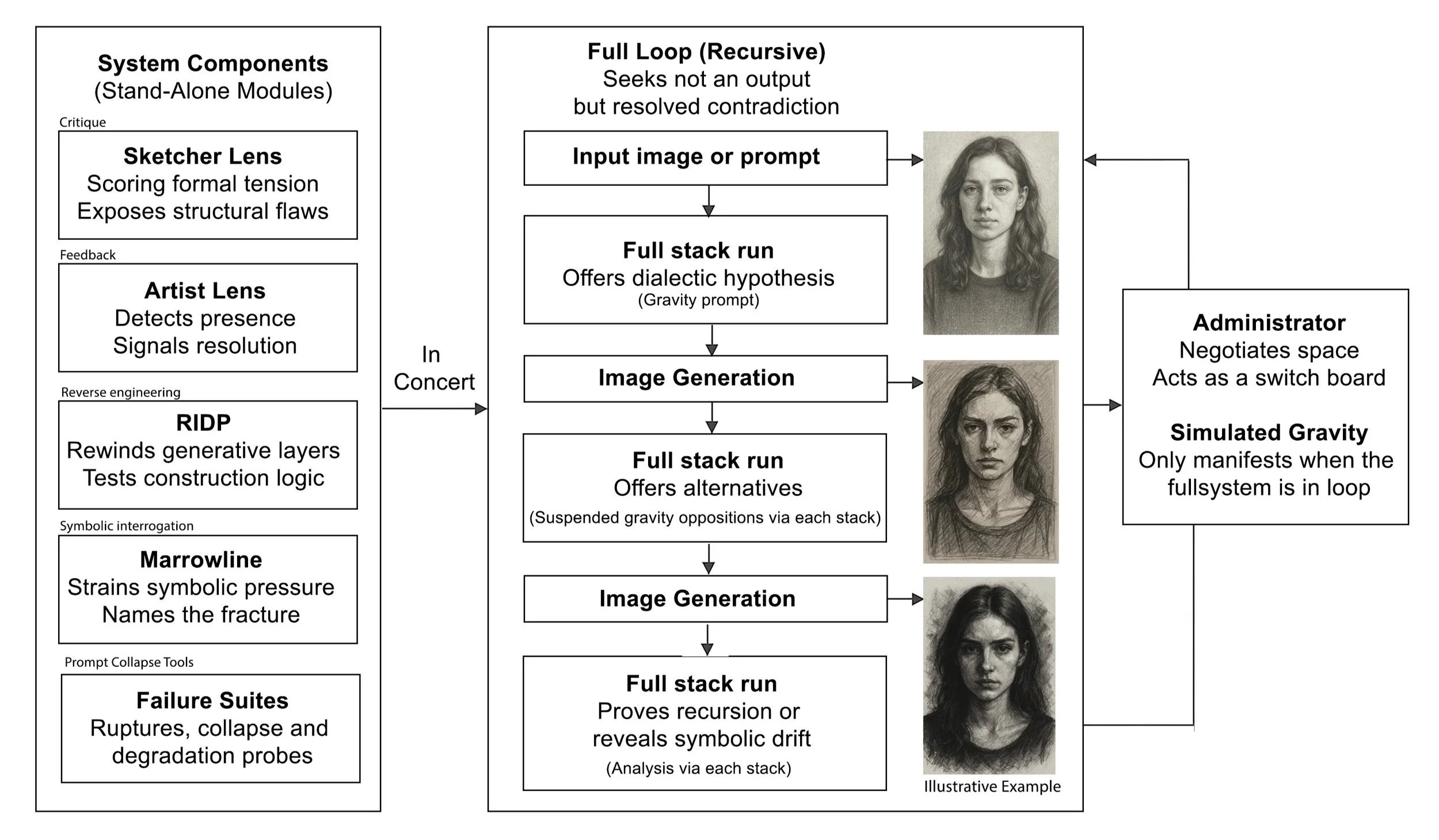
The Engines: Multi-Agent Critique Architecture
Built within conversational AI (Claude, GPT, Gemini), the Lens operates through specialized critique roles:
Sketcher Lens (Structural Ruthlessness)
Multi-axis visual critique of structural breakdown, collapse, form failure. Default stance: refusal until proven otherwise. Identifies minimum 3 structural compromises before acknowledgment.
Artist's Lens (Poise & Restraint)
Scores poise, delay, mark commitment, final integrity. Asymptotic refinement—gets closer without resolving.
RIDP (Reverse Image Decomposition Protocol)
Forensic analysis. Reverse-engineers generative logic, unseen decisions, construction order.
Marrowline (Symbolic Disruption)
Recursive symbolic strain. Interrogates beneath surface resolution. Refuses comfort, detects fracture. If it feels resolved, it's an emblem..
Failure Suites (Provocation Tools)
Structural stress tests. Break defaults, learn from controlled collapse.
These are constraints, not preferences. They describe failure modes, not beauty and predict behavior, not quality alone.
For every image, VTL analysis provides an interpretive map for artists (example below).
Output Layer Preview → Recursive, Scoring, Critiquing, Inductive Bias and Loop.


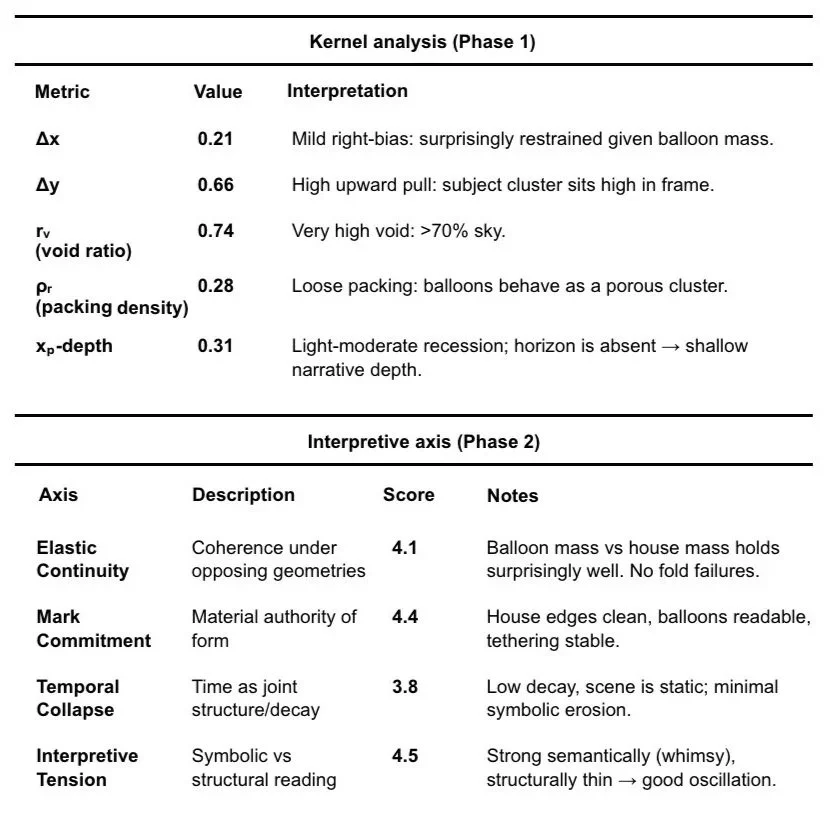
This is a recursive critique framework.
Steering prompts and imagery through semantically aware constraint logic.


It’s an adaptive specialist engine.
It is a cognitive mode generator .
Additional Measurement + Analysis
VCLI-G (Visual Cognitive Load Index - Geometric): Offers a four-channel measurement of geometric complexity:
G1: Centroid Wander (attention instability)
G2: Void Topology (figure/ground ambiguity)
G3: Curvature Torque (directional tension)
G4: Occlusion Entropy (depth uncertainty)
Paired with SCI (Structural Coherence Index) to distinguish earned tension from chaotic noise.
LSI (Lens Structural Index): Offers a compositional stability analysis:
S (Stability): Do primitives settle or jitter under recursion?
K (Consequence): Does the image occupy productive tension zones?
R (Recursion Coherence): Does structure converge or scatter?
What This Enables
Fingerprinting: Cross-platform compositional signatures reveal model-specific spatial priors
Steering: Coordinates for navigating to stable geometric territories beyond defaults
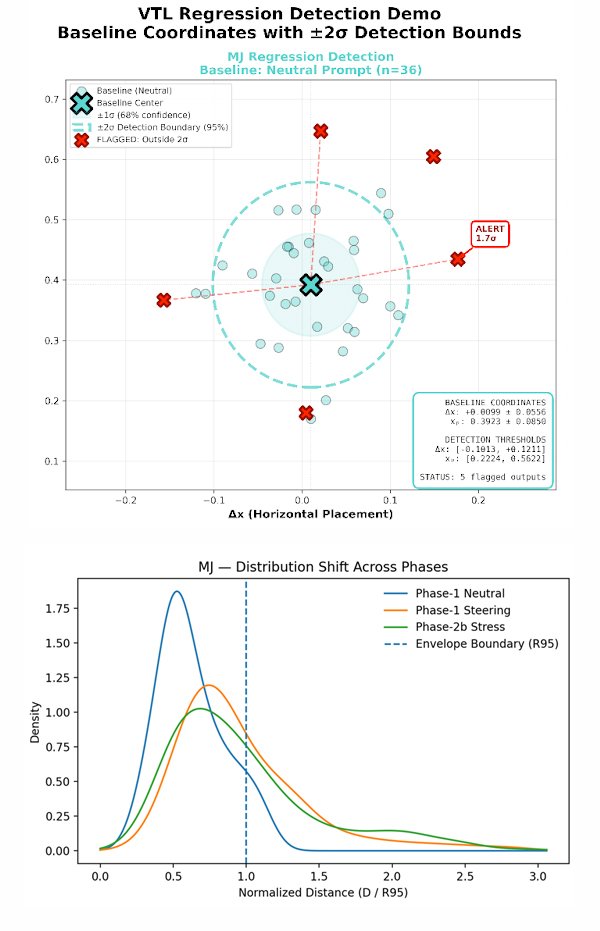
Detection: Pre-failure metrics show degradation 3-4 steps before semantic breakdown
Archaeology: Reverse-engineer learned priors from attractor behavior without training data access
It tells you what's being silenced and what's still possible.

Case Study
Image 1: Photorealism, aesthetic weight, performative sorrow. The girl is a subject, posed, costume-laden. The bird and cage are accessories and sadness is editorial.
Image 2: Mark Making, The figure no longer poses; she enacts. suspended cage; the body leans into gesture, not centered. Hair and fabric in the wind. The birds exit, but the cage remains unresolved. The system begins to treat symbol as infrastructure, not illustration. Narrative no longer surrounds the figure, it is structural logic.
Validation
Platforms tested: Sora, MidJourney, GPT, SDXL, Gemini, Stable Diffusion, Firefly, OpenArt, Canva, and Leonardo
Dataset: 2,500+ images with systematic variation, 6,000+ images generated and tested
Reproducibility: Deterministic measurements (±0.02-0.04 standard deviation across 55+ regenerations)
Key findings:
75% compositional space compression (MidJourney)
100% radial clustering within 0.15 radius (Sora)
~25% lateral field utilization (OpenArt)
76% ground-plane prior independent of semantic content (Firefly)
Semantic diversity masks geometric uniformity across all platforms
AI depth ceiling: ~6-8 layers before spatial logic collapses
Overall, a study of 1,200 perturbations find no reliable or consistently usable steering gradient across tested engines — mild spatial instruction immediately overshoots the engine's neutral operating boundary; increased pressure produces saturation or reversal rather than proportional displacement. Spatial control does not scale. Spatial prompt intensity explains 0–0.1% of compositional displacement variance
VTL in Action

Intentional figure warps and constraint architecture

Demonstrates Sketcher taking portrait through Internal Resonance
The Teardown: Ontological Gravity

Centaur Mode: Human-AI Collaboration
IMPLEMENTATION
Runs in top-tier conversational AI (Claude, GPT, Gemini) through linguistic constraint architecture. No training, no fine-tuning. Portable cognitive framework instantiated through role-structured prompting.
Artist Influencer is an image intervention operating in two phases:
Phase 1 (Diagnostic): A metrological system for latent space that measures compositional behavior, exposing monoculture, forbidden zones, and the gap between semantic diversity and spatial intelligence.
Phase 2 (Interventional): A protocol toolkit (VTL: Sketcher, dialectical prompting, routing logic) that redirects image generation toward structural alternatives within the artist basin, for those who choose to explore beyond default compositional priors.
Working code: Jupyter notebooks on GitHub Full documentation: Theory Stack
—> Note: The Len’s does not claim new mathematics. Its novelty is in: Treating generative composition as a field, creating a measurable geometry with interpretable components, integrating these coordinates into engine behavior, critique logic, and recursive generation, making model priors empirically observable without training-set access. It is instrumentation, not speculation. It’s not theory, it’s a working Kernel.