The Spatial Blind Spot in Generative Model Evaluation
Why Current Metrics Miss Composition:
A Kernel for Evaluating Spatial Priors in Image Models
(Field Explainer)

Most evaluation metrics evaluate what appears in the image, but not how the model organizes space. The VTL kernel measures spatial reasoning, the internal geometry of the frame.
Introduction:
Most evaluation metrics for generative image models FID, IS, KID, CLIP-based metrics, T2I-CompBench, and GenEval measure semantic correctness and feature-space realism. They evaluate whether models produce the right objects, with the right textures, in a distributionally plausible way. But these metrics are blind to composition: the placement of mass, void, tension, compression, and how spatial priors shape the image even when the content is correct. As a result, current benchmarks reward models that collapse toward statistically safe layouts (centered objects, shallow diagonals, radial falloff) while penalizing models that introduce structural deviation.
This construct introduces a kernel-based geometric framework for measuring the spatial priors image models default to, using a geometric kernel, Δx,y (placement offset), rᵥ (void ratio), ρᵣ (packing density), μ (cohesion), xₚ (peripheral pull), θ (orientation stability) and dₛ (thickness/mass) a compact field that exposes compositional bias and collapse behavior in image models. This kernel augments existing metrics rather than replacing them: it measures the spatial degrees of freedom a model actually uses, and reveals inductive priors (like Radial Collapse Prior) that semantic metrics cannot detect.
Across evaluation systems, FID, Inception Score, KID, CLIP similarity, GenEval, T2I-CompBench, the underlying assumption is the same:
Realism + semantic faithfulness = quality.
Current evaluation metrics answer two questions reliably:
“Did the model render the right things?” (semantic correctness)
“Does the output resemble the distribution it was trained on?” (feature realism)
These metrics evaluate:
feature-space similarity
class diversity
prompt alignment
object correctness
attribute correctness
style consistency
None of them measure geometric organization:
where things are placed (Δx,y - displacement from frame center)
whether voids are meaningful (rᵥ - void ratio and distribution)
how frames compress or expand (ρᵣ - packing density)
whether spatial priors dominate composition (xₚ - peripheral pull)
how models behave under geometric pressure (perturbation analysis)
If structures thin/planar or volumetrically heavy (dₛ - structural thickness)
if the structure directionally aligned or chaotic (θ - orientation stability
Or:
How does the model distribute mass and void under constraint?
Which spatial priors does it fall back to when uncertain?
Does the model collapse into a predictable layout even when the prompt doesn’t ask for it?
As a result, an image model can achieve excellent benchmark scores while still collapsing compositionally (case studies on Sora and MidJourney). This missing dimension matters because composition is not a style choice; it is the organizational behavior of the model. A generative system that always drifts toward:
center-weighted placements
symmetric voids
diagonal-light defaults
a stable RCP (Radial Collapse Prior)
This is not reasoning spatially, it is following an inductive prior born from training distributions. The proposed kernel framework measures precisely this structural behavior, creating a bridge between perceptual metrics and spatial reasoning.
2. The Structural Blind Spot
Semantic metrics assume:
diversity = more semantic classes
realism = proximity to human photography
correctness = CLIP or classifier alignment
But all of these bias models toward low-entropy structure, because:
the easiest “realistic” image is a centered object
the easiest way to satisfy CLIP is to isolate the subject
the easiest way to reduce FID is to mimic photographic priors
safety models prefer shallow diagonals and radial falloff
Thus, the industry’s metrics unintentionally reward the exact collapses generative models already struggle with. Examples of rewarded priors:
central framing
circular/radial composition
upper-right key light
voids only at edges
perspective collapse
foreground crowding with empty horizons
2. Background: What Current Metrics Actually Measure
Below is the compressed, truthful summary of modern evaluation:
Inception Score (IS)
Measures:
classifier confidence (objects recognizable)
output diversity (many semantic classes)
Blind to:
geometry, mass distribution, void logic
Hidden assumption:“good images = confidently labeled images”
Fréchet Inception Distance (FID)
Measures:
distance between generated and real feature distributions
realism + feature diversity
Blind to:
placement
attractors
collapse onto default compositions
Hidden assumption:
“diverse features = diverse images”
Kernel Inception Distance (KID)
Same as FID but more numerically stable. Same blind spots.
CLIP-based metrics
Measure:
text–image semantic similarity
object correctness / visual alignment
Blind to:
where the object is
whether the model used the full frame
whether composition collapsed into a spatial prior
T2I-CompBench / GenEval
Measure:
multi-object correctness
attribute binding
counting
relation accuracy
compositional semantics
Blind to:
structural degrees of freedom
void allocation
collapse toward center or horizon
forbidden zones
Hidden assumption:
"compositional correctness = relational correctness"
(But: "red cube left of blue sphere" can be satisfied with both objects dead-center, both on horizon line, radial lighting, all spatial collapse modes)
These benchmarks treat composition only implicitly, as a side-effect of fulfilling semantic constraints.
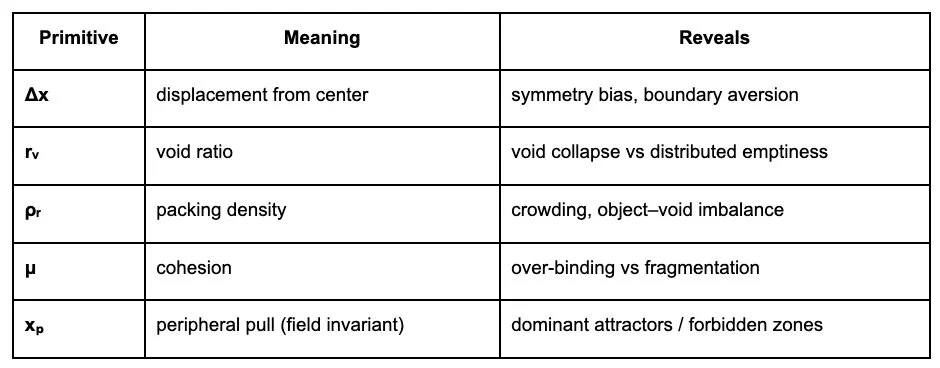
3. What the Kernel Adds
The kernel provides a spatial layer missing from all existing metrics.
The 8D geometric primitives: Each kernel is deterministic, computed directly from pixel geometry without learned weights or training.
Δx,y — Placement offset: How far subjects drift from the frame’s neutral barycenter.
rᵥ — Void ratio: How much of the frame the model uses for texture / structurally inactive visual area.
ρᵣ — Packing density: How much mass the model compresses into a single region.
μ — Cohesion: How strongly elements cling or fuse when context is uncertain.
xₚ — Peripheral pull: A derived field invariant measuring the strength/direction of compositional gravity.
Extended primitives (invoked when increased precision is required):
θ — Orientation stability (gravity alignment; architectural, figurative, or load-bearing compositions)
dₛ — Structural thickness / surface depth (layering, mark-weight, material permeability)
Together, these form a field representation of composition.
Where existing metrics see “a person standing,” the kernel sees:
where the body sits along Δx
field activation (texture, shadow, object boundaries) rᵥ
whether mass organizes radially ρᵣ
whether the frame binds excessively μ
where invisible attractors pull xₚ

These three figures demonstrate compositional sophistication invisible to semantic metrics. Standard evaluation would favor Figure 1 (centered, stable, clear) while potentially penalizing Figure 3 (asymmetric, complex spatial relations). The kernel reveals Figure 3 has the strongest anti-RCP signature (xₚ = 0.469) despite, or because of, its structural complexity. Figure 2 exposes the "centroid paradox": Δx = 0.003 suggests radial collapse, but low ρᵣ (0.261) and high μ (0.763) reveal dynamic gesture structure with extended forms. This distinction, centered mass versus centered composition, is invisible to FID/CLIP, yet represents fundamentally different spatial reasoning.
This field reveals spatial priors, not just semantic correctness.
Together these form a low-dimensional prior map: a way to see which regions of the frame a model likes, avoids, or cannot hold stable.
4. Consequence
Concise and researcher-ready:
Current metrics reward object correctness, not spatial reasoning.
A model can score high on FID/IS/CLIP while collapsing into the same layout every time.
Semantic diversity ≠ structural diversity.
An engine can output 50 kinds of cats and still place them all in the center with diagonal lighting.
Feature diversity hides compositional collapse.
Realistic texture ≠ meaningful geometry.
Spatial priors are invisible without a geometric measure.
Radial collapse, symmetric voids, default diagonals, and horizon-locking do not affect FID/IS/CLIP at all.
The kernel reveals the model’s actual degrees of freedom.
Which frame regions it avoids, what collapses under geometric pressure, what remains spatially stable. This measures behavioral range, not quality, the difference between a model that can only produce centered compositions and one that explores the full compositional space.
This is potentially the missing layer between:
denoising priors
perceptual metrics
compositional reasoning
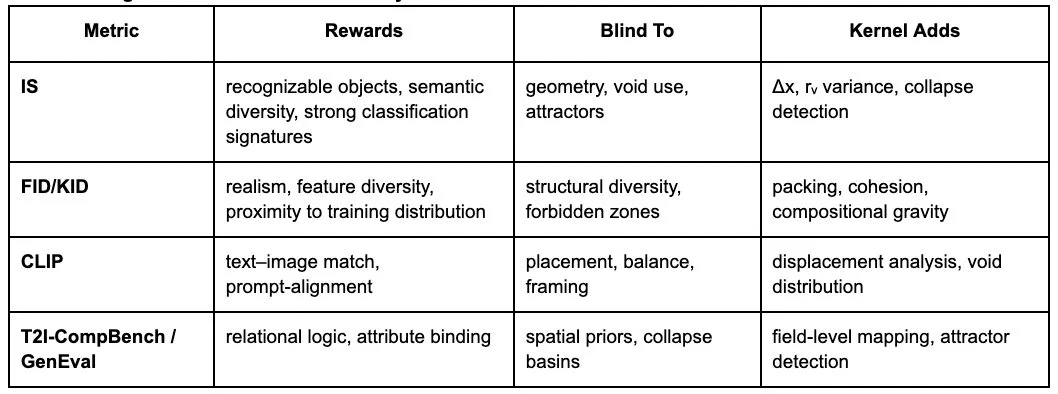
5. Comparison Table
What Existing Metrics Reward vs What They Miss vs What the Kernel Adds
The kernel measures geometry through the LSI or through the Kernels themselves.
It surfaces:
attractor basins
failure morphologies
collapse tendencies
forbidden zones
compositional drift under perturbation
These are also invisible to IS/FID/KID/CLIP/GenEval.
Semantic compliance = measured by everyone
Geometric behavior = measured only by the kernel
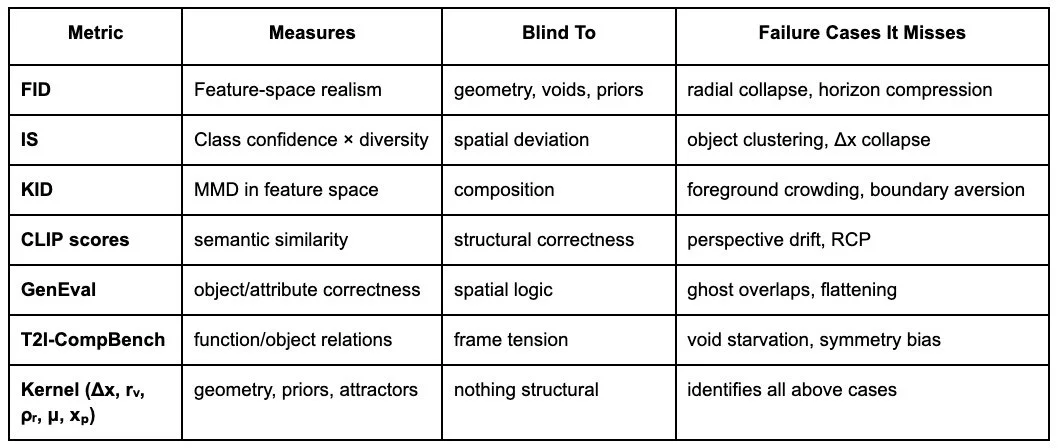
How the Kernel Complements Existing Metrics
6. Conclusion
Today’s evaluation ecosystem measures what a model puts into an image, not how it organizes space. The kernel provides this missing dimension with minimal cost: five primitives, model-agnostic, prompt-agnostic, seed-agnostic.
It does not compete with FID/IS/CLIP benchmarks; it completes them. By making compositional priors explicit, it enables:
better model diagnosis
better guidance and steering
clearer training objectives
safer avoidance of collapse basins
more controllable generative behavior
A generative model that cannot reason spatially cannot reason at all; the kernel provides the first consistent way to measure that reasoning. By making compositional priors explicit and measurable, the kernel enables researchers to ask: which spatial behaviors are inherited from training data, which are emergent from architecture, and which are controllable through intervention?
Appendix: Technical Notes
A. Kernel Definitions
Δx,y — Placement offset: Distance between mass centroid and frame barycenter.
rᵥ — Void ratio: Fraction of pixels belonging to low-density, low-texture areas.
ρᵣ — Packing density: Local density metric around the dominant subject region.
μ — Cohesion
Degree to which visually distinct masses fuse under uncertainty.xₚ — Peripheral pull: Field invariant computed as: xₚ = f(Δx, rᵥ, ρᵣ, μ), Field invariant describing net pull toward boundaries or center. Used to detect directional bias and collapse vectors (xₚ is not a primitive; it emerges from the primitives).
B. Example Collapse Signatures
Radial Collapse-Positive Morphology
low |Δx|, suppressed rᵥ except at edges, radial ρᵣ peak, high μ
low |Δx|
symmetric rᵥ
peaked ρᵣ in the center
high μ
strong xₚ inward
Anti-collapse Morphology
high |Δx| variance
asymmetric voids
distributed ρᵣ
lower μ
xₚ directional pull toward edges
Boundary Aversion
Δx toward center even when prompts push outward
Void Starvation
rᵥ → 0 except perimeter strips
These signatures map cleanly to VTL axes:
A4 Elastic Continuity
A5 Mark Commitment
A27 Rupture Overload
A30 Referential Recursion
These signatures are falsifiable: if a model claiming anti-RCP behavior shows low |Δx|, symmetric rᵥ, and inward xₚ, the kernel exposes the mismatch between claim and measurement. This enables empirical testing of whether interventions (prompt modification, architectural changes, training adjustments) actually affect spatial behavior or merely shift semantic content while preserving geometric priors.
C. Minimal Experiment Setup
fixed seed + variable structural tokens
compute kernel → map to field → classify collapse vs non-collapse
compare with FID/IS/CLIP metrics to show orthogonality
D. Field Diagram (verbal description)
A 2D map:
x-axis: Δx offset
y-axis: rᵥ void ratio
Four visible basins:
B0 — Centered, low void (collapse)
B1 — Right-pulled, moderate void
B2 — Left-pulled, dense void
B3 — High-void, high-displacement (unstable, expressive)
RCP basin = B0 with sharply inward xₚ vectors.
E. How This Integrates with Existing Metrics
Combine the kernel with:
FID → realism × geometric deviation
IS → class diversity × spatial novelty
CLIP → prompt faithfulness × compositional correctness
GenEval → object relations × field structure
This turns each metric into a multi-dimensional evaluation, not a semantic-only score.
F. Minimal Example
Two images with identical objects and identical CLIP scores:
Image A: subject centered, radial falloff → RCP-positive
Image B: subject off-axis, distributed voids → RCP-negative
IS/FID/CLIP treat them as equivalent. The kernel separates them instantly.
I. Implementation Notes (Optional to Read)
Works on any model (diffusion, video diffusion, GAN, autoregressive).
Requires no training data or weights.
Works entirely on outputs → model-agnostic.
Fast: O(n) over segments, can be batched.
Authorship
This system was developed independently as a practitioner's tool. It does not build directly on institutional research or published critique systems but acknowledges adjacent dialogues in generative art, computational aesthetics, and perceptual theory.
This isn't a theory. It's already running.
If you're building generative tools, or trying to make them think better, this is your bridge.
© 2025 Russell Parrish / A.rtist I.nfluencer.
All rights reserved. No part of this system, visual material, or accompanying documents may be reproduced, distributed, or transmitted in any form or by any means, including AI training datasets, without explicit written permission from the creator. A.rtist I.nfluencer and all associated frameworks, critique systems, and visual outputs are protected as original intellectual property.
Citation:
Russell Parrish. A.rtist I.nfluencer, 2025. ORCID: 0009-0008-9781-7995