What Firefly does by default
Compositional Stability, Spatial Priors, and Geometry-First Diagnostics
300 images. 100 prompts. 3 aspect ratios. Measured with the VTL Spatial + Color Kernel — a deterministic, model-free coordinate system for image structure. No aesthetics. No opinion. Just coordinates.

The structural signature
of Firefly.
Every finding is bootstrapped (n=10,000 resamples). All measurements are deterministic — same image produces the same output, every time.
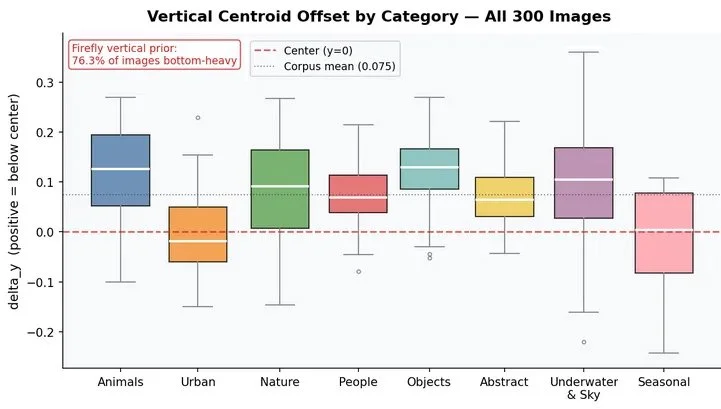
01 · Vertical Prior
76%
Images bottom-heavy
Visual mass sits below geometric center on 76.3% of all images regardless of prompt content, category, or format.
95% CI [71.3%, 81.0%] · t=12.77 · p < 10⁻²⁹
02 · Structural Modes
76%
Region-Field mode
Object-centric prompts organize into coherent stable regions. Distributed content (rain, foliage, crowds) exits this mode and the vertical prior disappears with it.
95% CI [71%, 81%] · vs 51% in TEXTURE_FIELD
03 · Chromatic Suppression
92.7%
"Color follows structure"
Color almost never creates its own structural boundary. 1 image in 300 carries the "color leads structure" tag. CBI mean = 0.020.
95% CI [89.7%, 95.3%]
04 · Aspect Ratio
Portrait equals Landscape
Departure from square drives the shift
Landscape and portrait shift compositional coordinates identically relative to square. Format direction is irrelevant. Only departure from square matters.
delta_y shift: +0.026 [+0.012, +0.039]
05 · Prompt Response
0.40
Max content sensitivity (η²)
Semantic category explains 20–40% of structural variance. Chromatic autonomy is least responsive (η²=0.05). Content moves the engine — selectively.
Permutation p = 0.0000 · n=5,000 shuffles validated
06 · Warm Binder
5.9%
Dark neutral fraction
Firefly achieves tonal closure without dark excavation. 65.7% of images have virtually no dark anchor. Warm hues dominate 2:1 over cool.
95% CI [4.6%, 7.3%] · chromatic prior #a27d59
THE VERTICAL PRIOR
76%
BOTTOM-HEAVY · t = 12.77 · p < 10⁻²⁹
Firefly places visual mass below the geometric center of the frame on 76.3% of all 300 images, across every category, every aspect ratio, every type of content.
Abstract forms. Space scenes. Gravitationless conceptual content. The prior holds. Prompts like "geometric shapes in space" still carry mean delta_y = +0.066. The engine applies the prior before content logic.
The noise experiment confirms this is behavioral, not geometric — the vertical prior decays toward zero under Gaussian noise injection, meaning it's reading real image content, not measuring frame geometry.

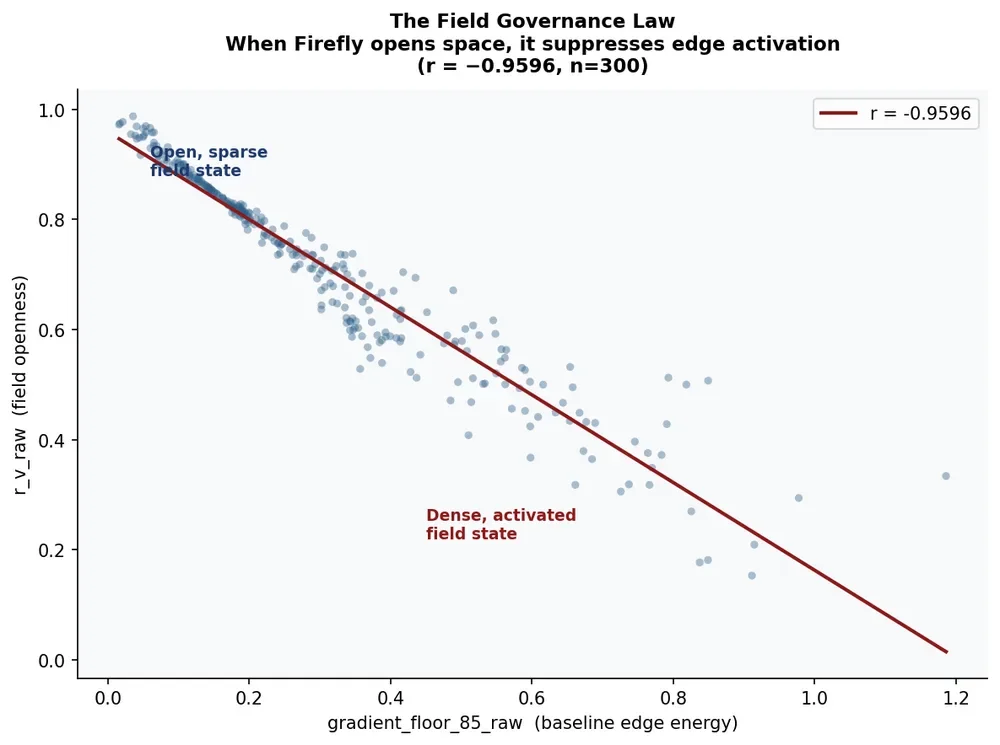
FIELD ARCHITECTURE
The field governance law.
When Firefly opens spatial field, it aggressively suppresses edge activation. The correlation between field openness and baseline edge energy is r = −0.9596 — 92% of variance explained. Not a preference. A structural constraint.
The engine almost never allows simultaneous high openness and high edge complexity. That combination — open atmosphere with violent edge detail — is what painters use to create perceptual pressure and unresolved depth. Firefly's field governance law prevents it.
The result is visual comfort and compositional stability. At the cost of structural tension.
r = −0.9596: Field openness vs edge activation · within narrow floor bands, r_v_raw retains std=0.038–0.105, confirming the relationship is empirical not definitional.
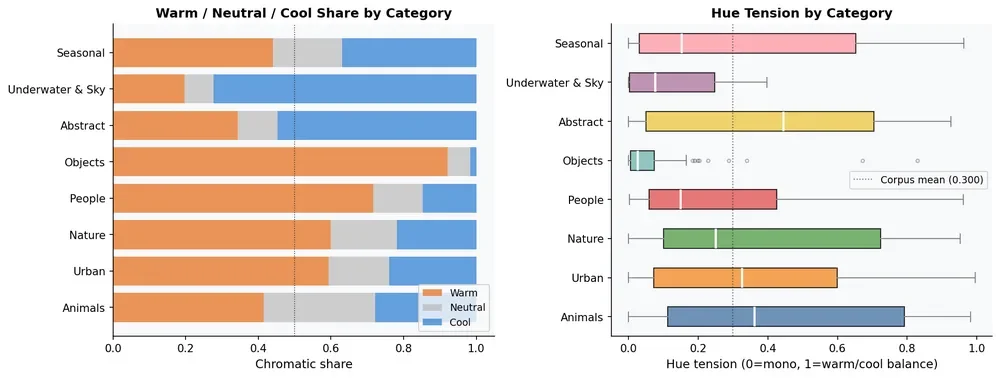
COLOR ARCHITECTURE
The warm atmospheric binder.
Firefly unifies images through warm atmospheric equalization rather than dark tonal anchoring. The result is coherent, workflow-compatible images — and compressed perceived depth.
Warm dominates 2:1.
Warm hues account for 56.3% of chromatic pixel weight. Cool hues: 28.1%. Orange and Red-Orange combined: 57.8% of all chromatic pixels.
Of all cool hues, 83% are soft — cyan and blue-green rather than pure blue. True blue participation: 1.6%. The engine routes cool content through hues that harmonize with the warm field rather than oppose it.
Warm / neutral / cool share by category (left) · hue tension distribution (right)
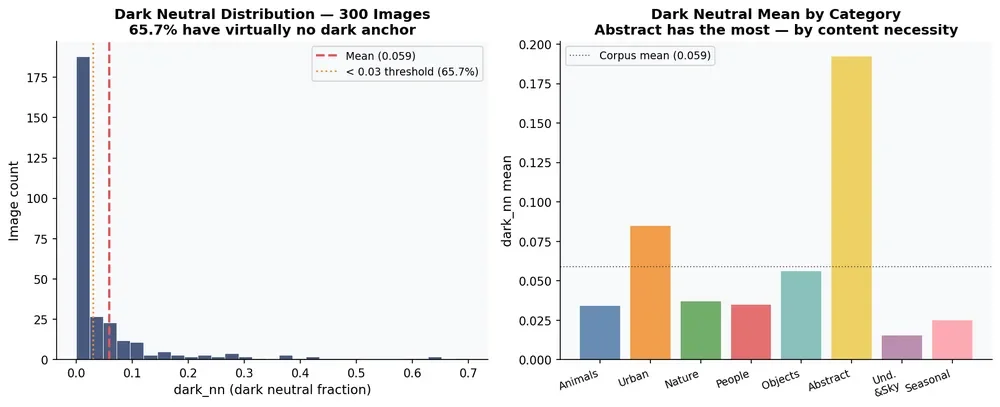
Closure without darkness.
65.7% of images have dark neutral fraction below 3%. Mean dark_nn: 5.9%. Shadows stay breathable. Values float upward. Images never collapse into deep dark.
The absolute tonal stack (fixed OKLab thresholds): 26.0% high-key · 49.3% midtone · 24.8% deep-dark. Midtone-dominant. Near-equal at the extremes.
Dark neutral fraction · 65.7% of images below 3% dark anchor
One Color is persistent: #a27d59
Chromatic prior · weighted mean of all
chromatic palette centers across 300 images.
Confirmed at both 768px and 1536px.
92.7% color follows structureColor reinforces luminance hierarchy. 1 in 300 images has color creating its own boundary. Color is atmospheric governance — not structural authorship.


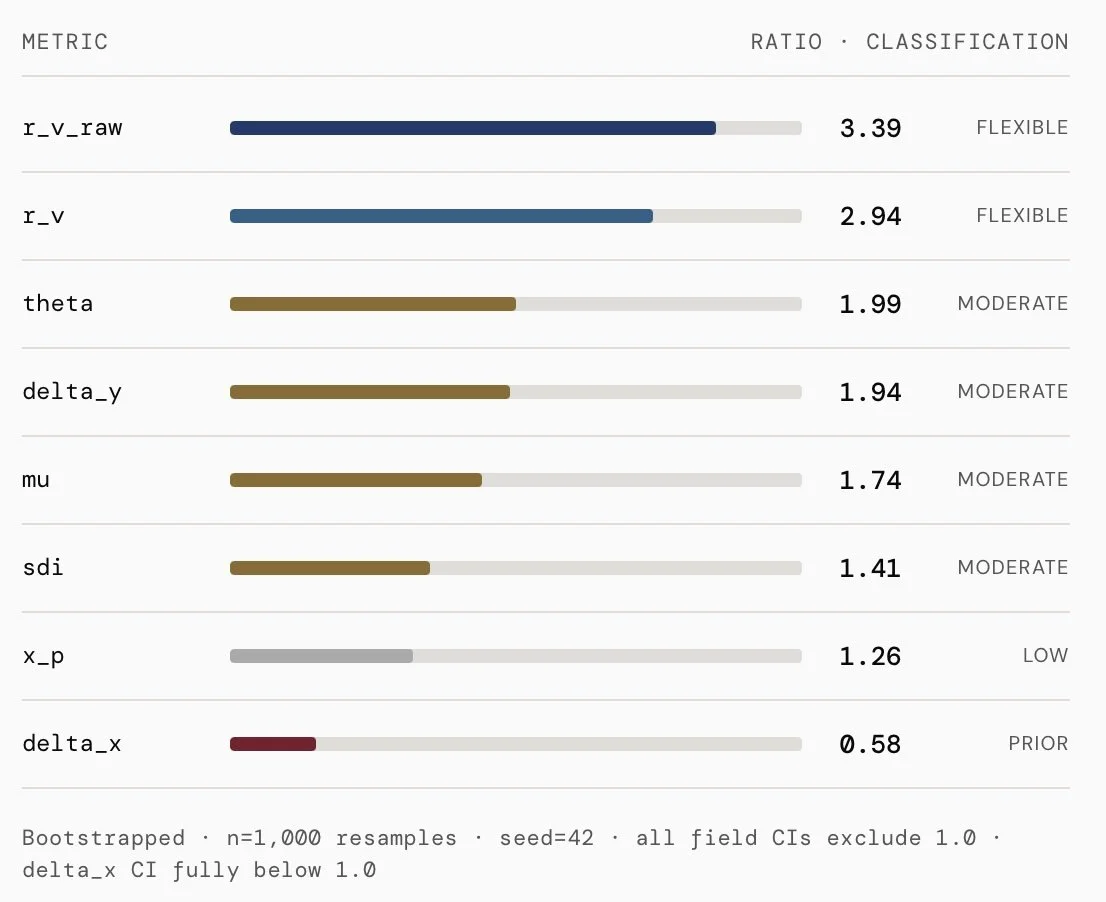
CREATIVE RIGIDITY · ENGINE FINGERPRINT
Semantic variation routed through atmosphere, not architecture.
The rigidity ratio answers: does changing the prompt drive more structural variation than changing the aspect ratio? When ratio > 1, prompts matter more than format. When ratio < 1, format matters more than prompt.
Field activation is 2.5× more semantically flexible than placement. A cyberpunk city and a rabbit in a meadow produce dramatically different edge densities. Nearly identical horizontal placement.
The engine changes what the field looks like. It rarely changes where things sit. The atmosphere becomes the semantic differentiator. The compositional architecture stays fixed.
delta_x = 0.58Format changes drive more horizontal variance than prompt changes do. CI: [0.49, 0.67] — fully below 1.0. Firefly has no horizontal compositional preference.
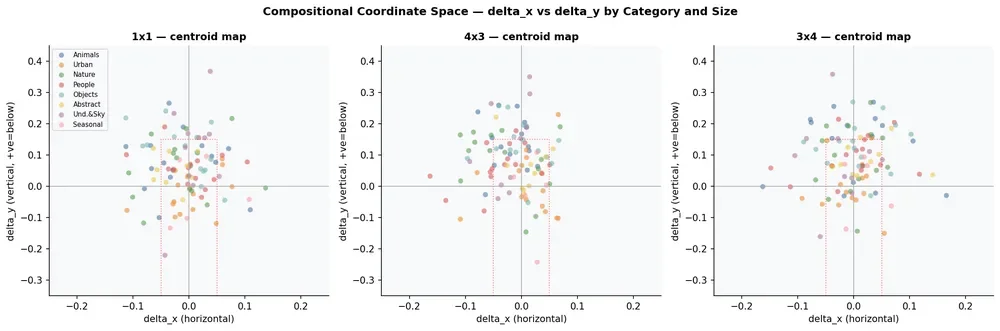
COMPOSITIONAL SPACE
Where Firefly places structure.
Each dot is one image. Horizontal axis = left-right centroid. Vertical axis = up-down displacement. Most images cluster below center across all eight semantic categories.
delta_x (horizontal) vs delta_y (vertical centroid offset) · all 300 images · colored by semantic category · red dashed box = central clustering band (±0.05 horizontal, +0.15 vertical)
INSTRUMENT & METHOD
How this was measured.
The VTL Kernel is deterministic and model-free. No learned embeddings, no aesthetic scoring, no semantic supervision. Same image → same output, every time, to floating-point precision.
Instrument: VTL Spatial + Color Kernel v0.4.8-standalone · Python · Google Colab. Tier 1 metrics are canonical and cross-run comparable.
Corpus: 300 images · 100 prompts · 3 aspect ratios (1×1, 4×3, 3×4) · 8 semantic categories · text-only prompts · default Firefly settings.
Statistics; Bootstrap CIs: n=10,000 resamples · seed=42. ANOVA validated by permutation (n=5,000 shuffles). All CIs are non-parametric.
Reproducibility: All Tier 1 metrics use classical CV operations only. Given the same image file, the kernel recovers identical values to floating-point precision.