Text-to-Image Models Have Spatial Biases. Now We Can Measure Them.
A geometry-first framework that measures how AI models actually organize visual structure, without aesthetics, semantics, or preference models.
Key questions:
Did this model change compositional behavior?
How do different engines respond to spatial instructions?
Where are the boundaries of controllability?
What are the default structural priors?

Current generative model evaluation relies on human preference models (subjective, expensive, slow to update), downstream task performance (indirect, task-specific), aesthetic scoring (taste-dependent, culturally biased), and single scores which miss multiple benchmarks. What's missing is direct measurement of HOW models organize visual structure.
VTL Kernel Metrics: A Coordinate System for Composition
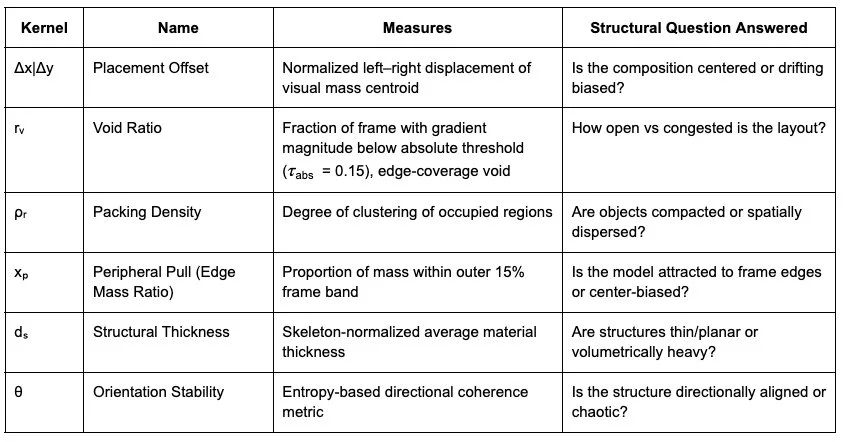
The kernel system locates generated images within a stable composition space using only structural signals extracted directly from pixel geometry with no learned embeddings, aesthetic scoring, or semantic supervision required. Think of it as GPS coordinates for visual structure.
What the Kernel Demonstrates
Three visualizations prove that structural behavior can be measured directly
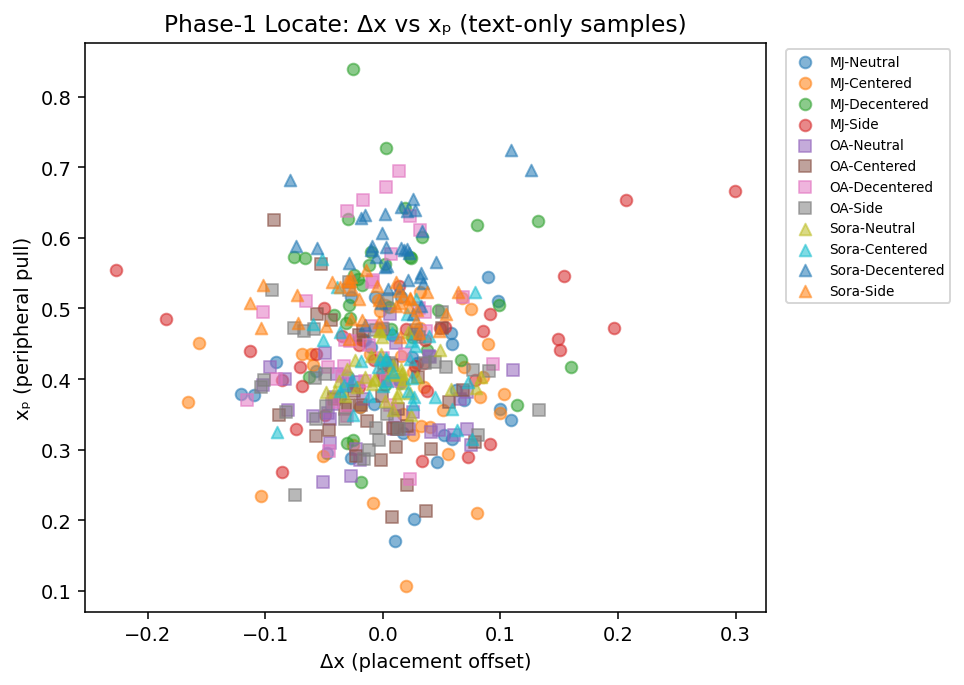
Proof 1: Engine Separation
Engines occupy distinct structural basins even before prompting begins. Under identical neutral instructions, MidJourney, OpenArt, and Sora produce outputs that cluster in different regions of composition space, revealing engine-specific spatial priors that persist regardless of semantic content.
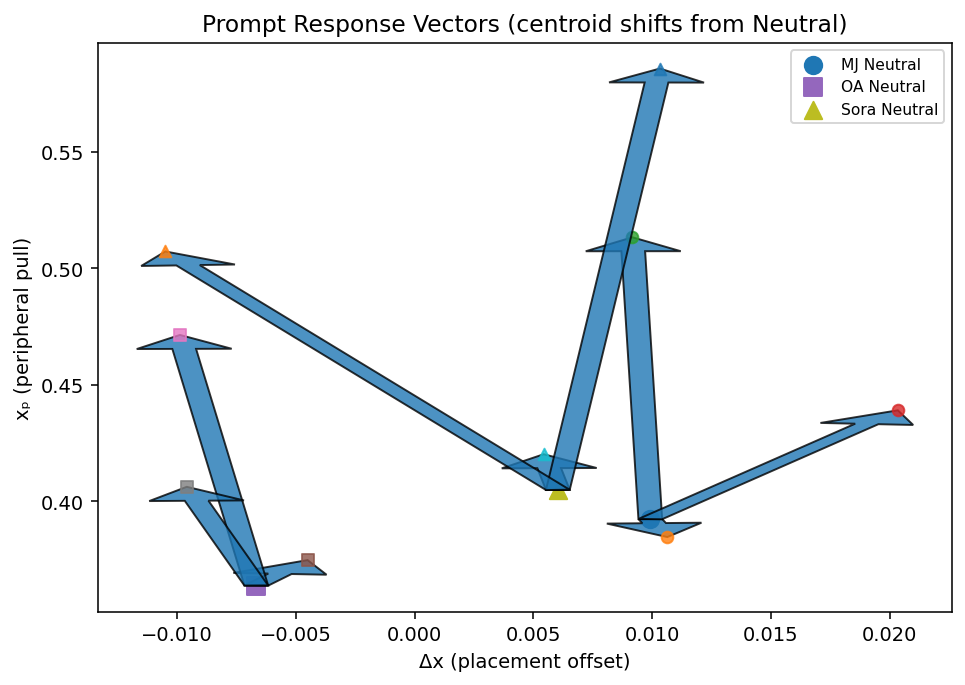
Proof 2: Prompt Responsiveness
Text: Compositional instructions produce directional structural movement. When prompts shift from Neutral to Centered, Out centered, or Sideways, kernel coordinates move in consistent, measurable directions, but each engine responds differently, revealing its unique compositional fingerprint.
Proof 3: Snap-Back Resistance
Models resist structural deviation with measurable force. Some engines allow compositional displacement, while others pull aggressively back toward their default layout basins. This "snap-back" behavior quantifies how strongly an engine enforces its spatial priors.
Methodology Section
How We Tested It

Test Design: Four-prompt gradient designed to probe spatial control boundaries: Neutral (baseline), Centered (explicit centering), Out of centered (edges, empty center), Side (asymmetric placement). These function as structural forcing functions rather than creative prompts.
Sample Coverage: 432 total images across three engines (MidJourney, OpenArt, Sora), three aspect ratios per engine (1:1, 2:3, 3:2), and 36 samples per prompt condition. Seven geometric kernels extracted from each image.
Analysis: Statistical comparison across prompt conditions to identify constraints, behavioral resistance patterns, engine-specific variance characteristics, and cross-platform structural rigidity.
One.
Engines Have Compositional Fingerprints: Different generators occupy distinct structural regions with separation (0.622 kernel units) larger than within-engine variance (~0.5), proving engine priors are distinguishable at baseline
What We Discovered
Two.
Aspect Ratio Modulates Control: Format interacts with structural compliance, resistance patterns change across 1:1, 2:3, and 3:2 formats, revealing that compositional behavior isn't format-invariant.
Three.
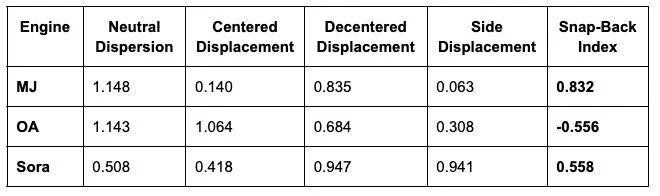
Default Priors Persist Under Pressure: Even explicit decentering prompts face measurable snap-back toward default composition basins, with MJ showing the strongest resistance (0.832) and OA showing inverted behavior (-0.556).
Four.
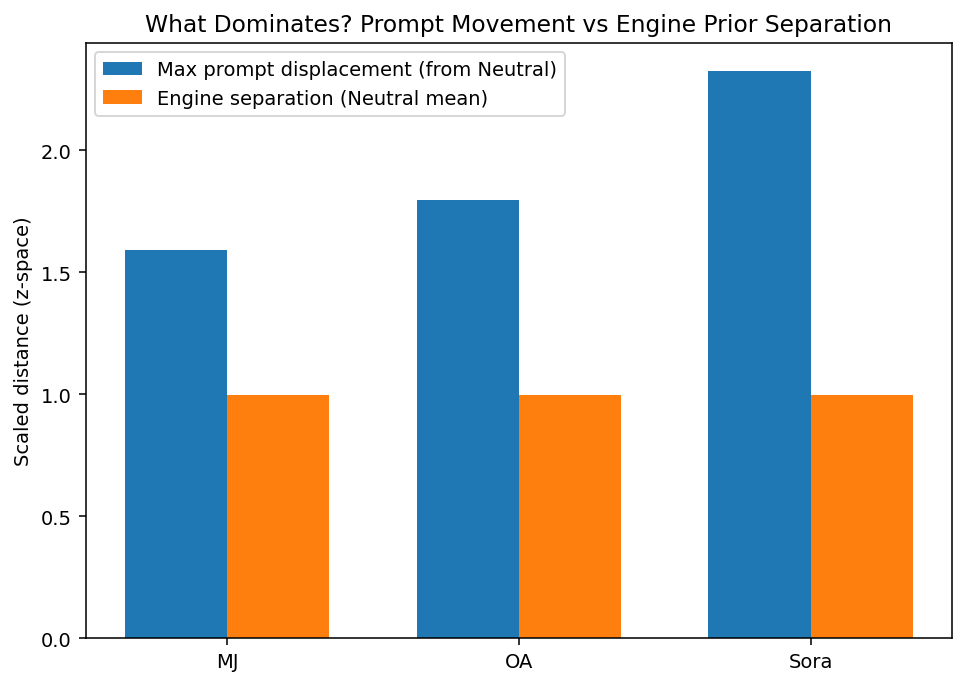
Side Prompts Are the Strongest Probe: Side instructions produce the largest structural displacement (2.64 mean z-distance), weakest snap-back, and strongest inter-engine divergence—making asymmetric placement the most informative compositional stress test.
What This Enables
Regression Testing: Detect compositional drift across model versions by comparing kernel distributions before and after updates. No human labeling required.
Benchmarking: Compare spatial responsiveness across models objectively using standardized prompt gradients and geometric metrics rather than preference votes.
Interpretability: Make spatial priors observable and quantifiable, revealing default basins, resistance patterns, and controllability boundaries that are currently invisible.
What This Framework Doesn't Do
This framework measures structural displacement, not semantic content (hate speech, policy violations), aesthetic quality (beauty, professionalism), concept manipulation (steganography, triggers), or causal mechanisms (why snap-back occurs). VTL reveals WHAT models do structurally. Other systems are required to evaluate WHAT they generate semantically.
Baseline dependency: Anomaly detection requires defining "normal," and different use cases require different thresholds
Measurement precision: Signal-to-noise varies by scene class; multi-object planar scenes produce cleanest signals while portraits and abstracts show higher variance
Built for Replication
Body text: The entire protocol is deterministic and standardized. Multi-object planar scenes with natural lighting, four-prompt gradient, three aspect ratios per engine, 12 samples per condition. All kernel definitions are frozen with no learned components or parameter tuning. The protocol can be rerun post-update to detect drift.
Generate Image → Extract Kernels → Locate in Space → Compare