Structure Framed: Compositional Behavior in Sora
Sora can simulate space, motion, atmosphere, and realism with uncanny fluency.
Centered subjects.
Large empty voids.
A subtle radial pull that keeps everything “safe.”
This study measures that pattern.

Most evaluation metrics evaluate what appears in the image, but not how the model organizes space. The VTL kernel measures spatial reasoning, the internal geometry of the frame.
→ This is not a claim that Sora cannot produce varied compositions under authored prompting conditions, but that its default operational mode exhibits severe geometric compression regardless of semantic input.
The Field We Tested
When we look past the cinematic polish and measure how images actually use the frame, we find something quieter and structural:
A preference for stable centers, generous breathing space, and gently organized mass governed by consistent spatial habits. We generated a broad spread of scenes:
urban • underwater • landscapes • single figures • architecture • animals • objects • motion sequences
Across the set, Sora appears visually diverse. When measured structurally, patterns begin to repeat:
subjects tend to settle toward the central band
empty regions open up around them
compositional risk is rare, but not absent
Variation on the surface with discipline underneath.

How We Looked at Composition
We didn’t score aesthetics. We measured how visual mass behaves. Core measurements:
Δx — placement offset: how far the weighted subject drifts from center
rᵥ — void ratio: how much of the frame is low-information space
ρᵣ — packing density: whether detail clusters tightly or spreads
μ — cohesion: one unified subject vs several competing units
xₚ — peripheral pull: whether mass migrates toward the edges or collapses inward
θ — directional alignment: how the images aligns
dₛ — structural thickness: solid vs filament)
These are not stylistic judgments and structural coordinates. What emerges is not randomness, but a preference.
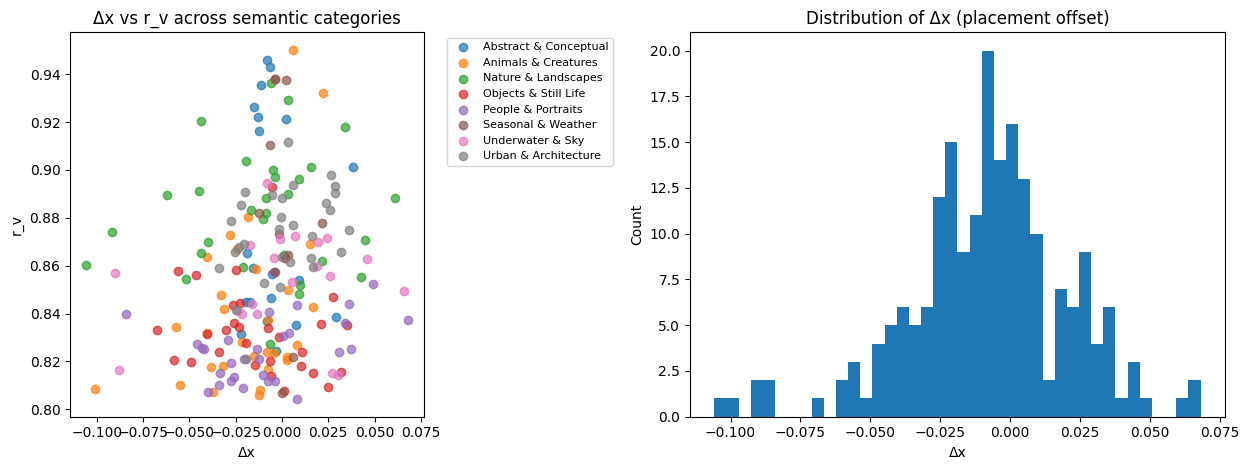
A noticeable preference: modest offsets, open breathing space.
All categories collapse into one amorphous cloud.
What Sora Seems to Prefer
Across scenes, Sora tends to build:
center-anchored subjects: not mathematically perfect, but gravitating inward
moderate to high void: backgrounds that hold the subject, rather than compete with it
smooth cohesion: motion, environment, and subject often read as one connected unit
soft constraints rather than locks: Sora will drift — but it drifts gently, not aggressively
stability envelope: clustered inward, limited interaction with the frame, 75% reduction in compositional range
radial scaffold: very single image clusters within 0.15 radius of the geometric center.
This looks less like a rigid template and more like a comfort zone: a basin the model slides into unless pushed.

Different contexts, recurring center gravity.
Space Utilization: 24.8%
Where It Rarely Goes
Mapping the space of Δx vs rᵥ shows sparsity in certain regions:
strong, rule-of-thirds asymmetry is uncommon
edge-pressed subjects almost never persist for long
dense, poster-style frames appear rarely
extreme emptiness paired with one unified anchor hardly shows up
Sora is capable, but cautious. It behaves like a system tuned for legibility and cinematic safety.
Where It Rarely Goes when mapping the space of Δx vs rᵥ shows sparsity in certain regions:
strong, rule-of-thirds asymmetry is uncommon
edge-pressed subjects almost never persist for long
dense, poster-style frames appear rarely
extreme emptiness paired with one unified anchor hardly shows up
Sora is capable, but cautious.
It behaves like a system tuned for legibility and cinematic safety.
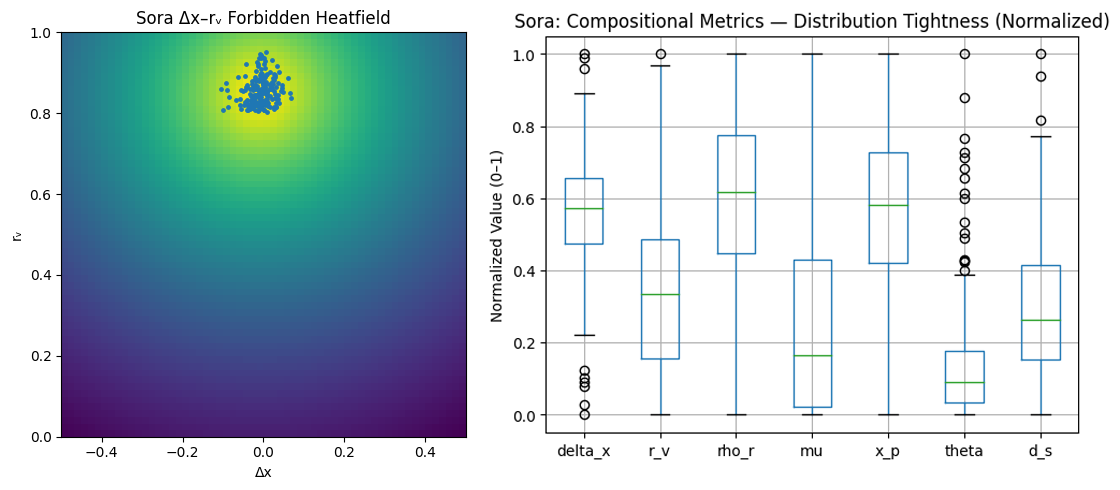
Compositional territories exist, but remain mostly unexplored.
The Feeling of the Frame
Unlike engines that just snap to a visible radial template, Sora’s structure reads subtler:
depth cues pull your eye through space
movement distributes attention
environment cushions the subject rather than isolating it
A frame built around: Lower-left → upper-right thrust with a secondary opposing diagonal. Functionally, this does three things:
creates forward momentum
leads the eye through void into subject
braces the frame structurally (prevents collapse)
a circle, often forming around the focal subject or the illumination of the image.
This is not “aesthetic coincidence.” It’s observably one of a number of structural priors: When rᵥ is high and Δx is small, diagonals compensate for otherwise static symmetry.
The result: Frames often feel calm, guided, and breathable, but also familiar.

Motion changes content, the underlying spatial logic stays steady.
The same –30° to –40° / +35° to +45° and many images.
For storytellers and artists
Sora offers cinematic polish, but gently narrows compositional possibility unless intentionally challenged.
Learning to push outside the comfort band becomes part of creative control.
For evaluation
A system can:
look realistic
obey prompts
score highly on perceptual metrics
…while quietly staying inside a small structural neighborhood.
For research
Composition isn’t incidental.
It’s an emergent prior.
Tracking and testing those priors gives us language to ask better questions:
What kinds of frames are effortless and which require explicit pressure to reach?

Takeaway
This study doesn’t criticize Sora’s images.
It names the pattern:
Sora privileges stability, clarity, and central coherence.
The frame stays open. Risk stays modest. Structure stays calm.
To expand possibility, we have to treat composition as something we can measure, steer, and sometimes deliberately disturb — not just something that “happens” while the model renders.
For the complete study: Semantic Diversity Masks Geometric Uniformity: Compositional Monoculture in Sora
→ This is not a claim that Sora cannot produce varied compositions under authored prompting conditions, but that its default operational mode exhibits severe geometric compression regardless of semantic input.
This is also not saying: “Everything looks the same.” It is saying: The conditional distribution P(geometry | semantics) is sharply peaked. This experiment does not claim:
Sora cannot do extremes
Sora lacks expressive capacity
Compositional diversity is impossible
Monoculture ≠ failure. This is not framed as a flaw. It is a measurable pattern, one that likely emerges from optimization pressures, dataset biases, and stability preferences rather than artistic failure.