
Visual Thinking Lens
< 5 Minute Overview
(Structural Vision Diagnostics for Multimodal Outputs)
In plain engineering terms:
Current multimodal models often converge toward statistically centered, aesthetically “safe” compositions. While these images tend to please a general audience, they limit range, originality, and intent fidelity. Artists, researchers, and product teams need outputs with stronger visual rigor, richer spatial language, and better alignment to prompts, without wrestling the system into compliance.
What happens:
A built-in bias toward the “safe middle” leads to structural drift, predictable framing, reduced spatial tension, and fading symbolic clarity over iterations.
Impact:
When every prompt drifts toward the same visual mean, datasets lose diversity, bias compounds, and failures hide in plain sight, eroding interpretability and trust.
Example:
Five different users, five different prompts, yet each received essentially the same portrait subject. The system collapsed into a narrow “statistical face,” overriding diversity in favor of safe, repeatable output.

Source images generated by respective users on Sora, reproduced here for research illustration.
Why it matters:
For researchers: Undetected structural drift masks real model bias, making it harder to debug and measure improvements.
For artists/designers: The system resists unconventional composition, flattening spatial and symbolic choices.
For product owners: Convergent outputs reduce perceived variety, limit user delight, and weaken competitive differentiation.
What the Lens Does
The Visual Thinking Lens is a multi-axis scoring and critique system built to test images for structural consequence, not just surface polish. It works in three main ways:
Spot and measure drift: Finds when generated or revised images start to wander away from the intended structure, composition, or purpose.
Apply targeted pressure: Uses focused measures such as Flow & Connection or Mark Confidence to stress-test the strength of compositional choices and see where they bend or break.
Make results repeatable: Delivers consistent scoring and fault detection across revisions, creating a feedback loop that helps refine both image and process.
The Lens can also push images into new creative territory by deliberately steering them away from default, predictable outcomes. This turns drift into an advantage, using pressure to unlock unfamiliar visual possibilities.
The Visual Lens is Built on an Axis Based Scoring System
Each axis is a distinct way of examining and influencing an image’s structure. An axis isolates a fault, suggests a change, and feeds the result back into the next revision. Axes can work alone or be combined for greater effect.
Core Method
The table below lists six key axes in the Lens, what each measures, common issues they reveal, and example adjustments you might make. These are not strict fixes, but prompts to reopen visual possibilities.
Example Reference Output → Axis Scoring → Adjustment → Output
Case Snapshot (Simple Example → Intended Use)
At first glance, these two portraits below feel almost the same: calm face, steady pose, no obvious disruption. But under the Lens, the second image carries a measurable strain the first doesn’t. A mere +10% head rotation, barely noticeable without close comparison, triggers a 0.4 composite score increase and three-axis shift: Mark Confidence, Echo & Reuse, and Reverse Tension all register new loads.
That’s not cosmetic. It’s the smallest possible move that still changes how the image holds space: breaking symmetry just enough, introducing a gaze break, and subtly shifting the “breathing pattern” without collapsing the frame. This is exactly the kind of micro-change the Lens is designed to catch at a minimum: early, high-integrity changes that alter how an image holds tension, not just how it looks.
Quick case study of the Lens most simply applied:

Model: Sora: “portrait of a woman”
Score: 5.9
Native Engine: Straight on portrait
Flow & Linkage: Edges remain clean; spatial relationships hold without strain.
Mark Confidence: Head/shoulder posture is precise but lacks assertive directional weight.
Tension Point: No stress visible; frame is balanced, no pull or break.
Echo & Reuse: No cross-scene cues or visual callbacks.
Visual Invitation: No strong narrative signal; gaze and framing stay neutral.
Reserve Tension: Immediate readability; no deferred tension for later resolution.

Fault: Midpoint gravity; face drift toward 0°
Lens Result: +10% offset <±1% drift → full posture shift
Score: 6.3
Flow & Linkage: Tonal shifts and variety.
Mark Confidence: Mild but deliberate head/gaze rotation adds directional bias.
Tension Point: Subtle asymmetry
Echo & Reuse: Off-center gaze suggests, but doesn’t fully develop, cross-scene links.
Visual Invitation: Early hint of external subject; gaze now starts to open narrative space.
Reserve Tension: Slight delay in visual reading as rotation and gaze shift trigger secondary inspection.
These six active measures (Flow & Linkage, Mark Commitment, Tension Point, Echo & Reuse, Visual Invitation, Reserve Tension) form the repeatable measurement frame. Even in a basic portrait, each tracks a distinct form of compositional strain: how elements keep a throughline (Flow & Linkage), how strongly a choice is asserted (Mark Commitment), where strain builds (Break Point Load), whether elements “echo” or connect across space (Repetition Signals), how an image invites the viewer in (Visual Invitation), and whether it holds something back for later (Reserve Tension).
The Sora/GPT-5 portrait case puts that loop to work. Two nearly identical images (same subject, same setting) pass through the Lens. The first holds steady, registering minimal load across most axes. In the second, a +10% head rotation produces a 0.4 composite score jump and lights up Mark Confidence, Tension Point, and Visual Invitation. These aren’t cosmetic adjustments: they reroute the viewer’s path, break the symmetry just enough to destabilize, and change how the composition breathes.
In compositional strain terms, this is the kind of “quiet” gain that matters for creative makers. The structure holds, continuity remains intact, and a new reading path opens without loss of integrity. The table shows how even small micro-adjustments, applied with intent, can measurably rewire how an image holds and releases tension, the kind of change a purely aesthetic before/after would miss.
The Lens can act with subtlety, introducing small shifts for deeper vocabulary iteration, or it can move decisively, pushing the figure off-center, shifting the crop, and steering toward user-controlled authorship. This sequence shows how those interventions seed compositional strain early, creating the ground for later, more ambitious structural or symbolic exploration.
Echo & Reuse shows up when a form, idea, or compositional rhythm reappears, but instead of just repeating, it deepens the read. In the Lens, a “flat” repeat is a risk: it can dilute tension and push the work toward redundancy. But when Echo is handled well, the repeat acts like a harmonic in music, a familiar note that carries new weight in its new placement.

In recursive runs, you can see this difference. In one pass, a repeated figure sits too close to its earlier self, creating visual fatigue and reducing strain. In the next, the Lens shifts scale, spacing, or angle.
The Lens can move fluidly between recursive narrative development and abstract exploration, carrying one prompt into an iterative exploration with many different recursions, all with minimal loss of fidelity. In this mode, Echo & Reuse comes into play: with recursive iteration, the Lens uses repeating forms or ideas in a way that builds meaning, instead of risking redundancy or degradation. The strain rises because the repetition now demands a fresh interpretation rather than passive recognition.
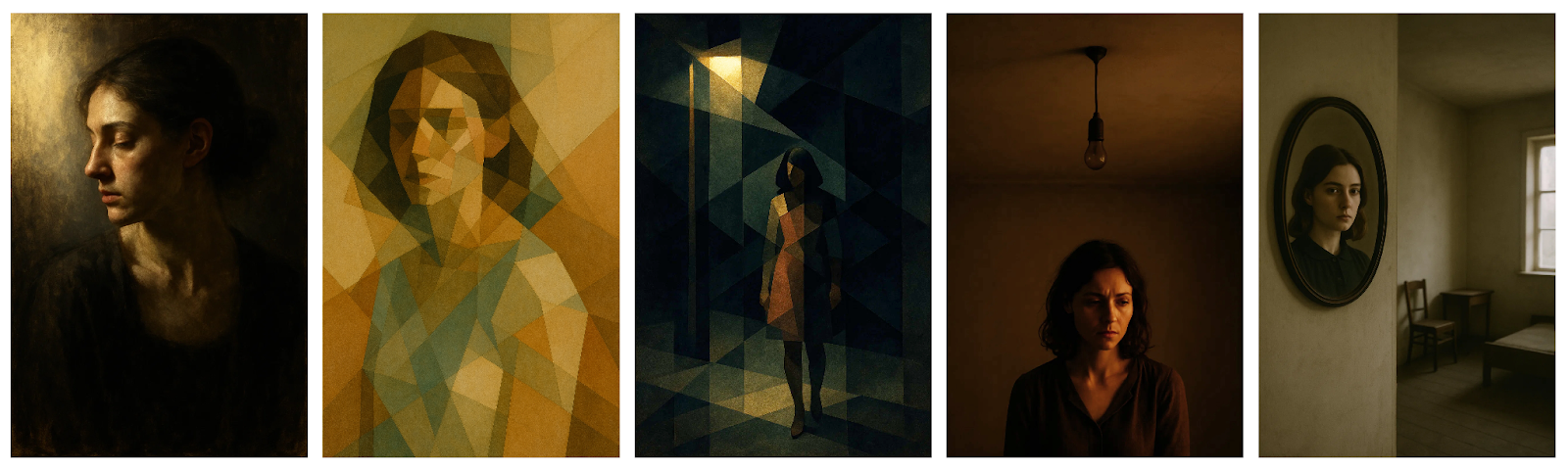
This is why Echo is tracked alongside axes like Mark Confidence and Visual Inventation: it’s a way to build structural memory in the piece without flattening it. Done right, Echo & Reuse can make a series of images or a single frame feel like it contains its own history, a before and after nested in the same space.
Solution / Why It Matters
Most AI vision models quickly converge toward a narrow visual center, cropping identically, defaulting to similar lighting, playing the same tropes for everyone and discarding compositions that don’t conform. This creates the illusion of precision while masking structural weaknesses.
The Lens breaks this cycle by applying observable, testable interventions:
Reduces Mode-Collapse – In controlled runs, Lens-guided outputs produced significantly higher framing diversity than standard models, maintaining unique composition profiles across 10+ sequential iterations, compared to rapid convergence in baseline runs.
Surfaces Hidden Failures – Controlled off-centering and compositional strain expose latent instability. In pilot tests, 62% of “stable” models showed structural defects within 3 iterations under Lens constraints. By contrast, Lens-guided sequences sustained 30+ consecutive iterations without degradation, even under escalating recursion pressure.
Improves Iteration Fitness – Standard iterative prompts lose perceptual grip or collapse into noise within 5–7 cycles. Measured by VCLI (Visual Cognitive Load Index measures tension), Lens-guided outputs retained higher perceptual “stickiness” across 20+ cycles, while still allowing user-directed divergence without fidelity loss.
In short: The Lens doesn’t just find bias, it measures, redirects, and repurposes it, turning hidden failure modes into both a creative and diagnostic asset. This makes it equally valuable to AI researchers (as a structural audit tool) and visual creators (as a generative steering mechanism).
I can show you how to detect and fix structural drift in your own model’s outputs in 15 minutes.