
A.rtist I.nfluencer is a recursive lab for visual intelligence.
Don’t just make images. Interrogate them. Remake them into images that speak.
Introducing a critique system for both AI-generated and user inputted visuals. A set of tools that apply pressure to the underlying structure of diffusion, prompting, composition and remaking.
This isn’t about surface or style. It’s about consequence.
This is a Visual Lens system that outputs:
Image critique with simulated scoring and reverse-engineered failure detection
Prompt layering and generation for recursive improvement
A system of 60+ axes, directions, and vocabulary sets, yielding millions of possible iterations
A system for artists and makers to learn, iterate and design
A five-layer architecture, fully logical, no code
A voice stack of four distinct interpretive roles
Each tool exploits GPT’s token-level manipulation, giving richer, more complex imagery
No front or back-end code. Just emergent architecture and some playful ontological gravity.
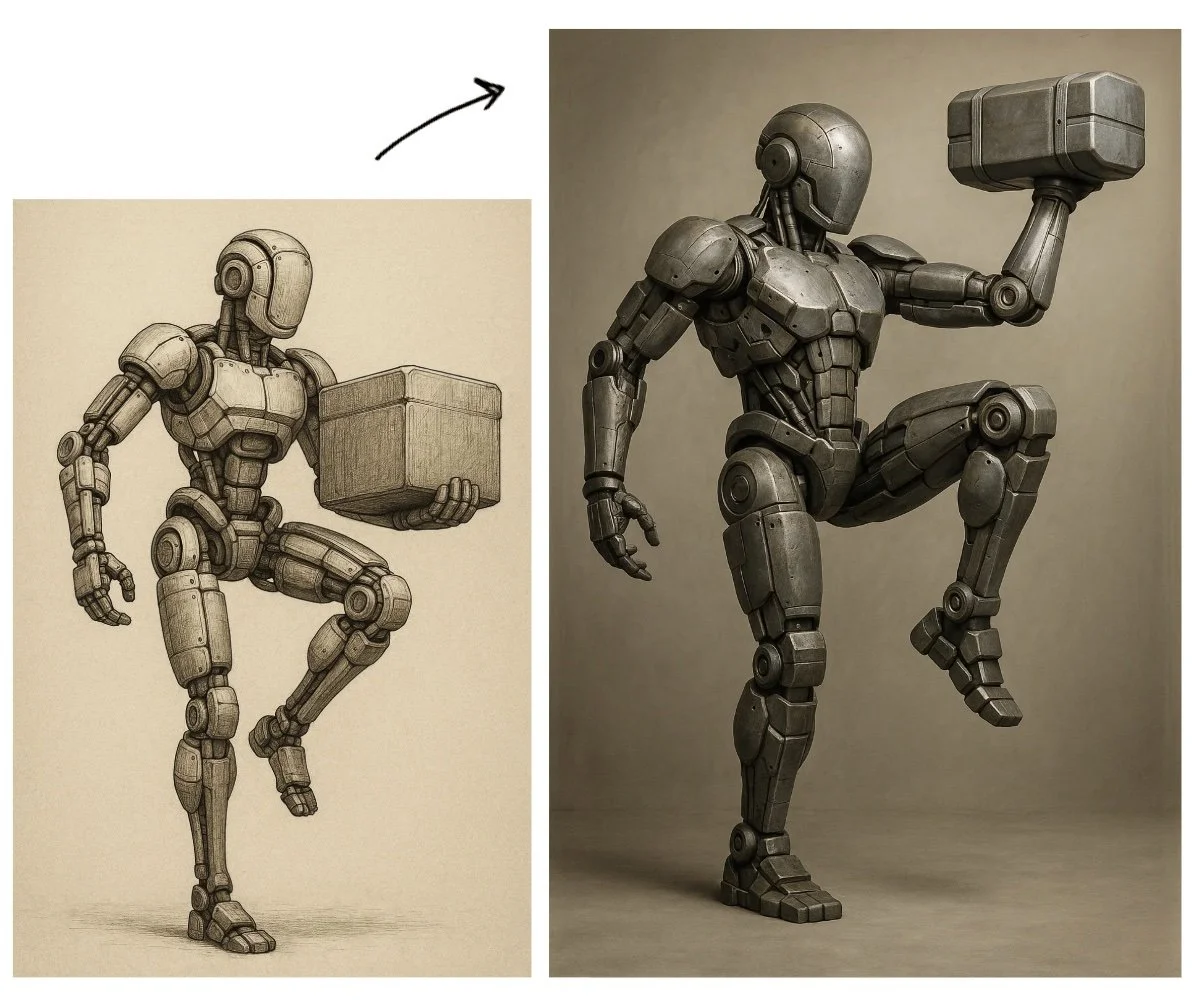
This isn’t a style generator. It’s a structural interrogation.
Generative art is exploding, but no one’s asking how images mean.
Artists are also trying to learn and adapt, with a system built on a vocabulary of aesthetics.
A.rtist I.nfluencer is a visual lens framework that dissects imagery and AI outputs, diagnoses image logic, and rewires how machines understand art.
This Visual Thinking Lens is that map.
It doesn’t style-shift. It tension-tests.
It’s a system artists, engineers, and models can all step into.

Why It Matters
Visual AI is scaling. Fast. Billions of images, no checks.
No shared vocabulary of structural failure. No test of tension. No map. Limited visual intelligence.

A.rtist I.nfluencer is a multi-agent critique system.
This Image Generator Lens is a cognitive meta-stack operating within a single-threaded LLM environment. It functions as a multi-agent system in orchestration, with distinct roles and interlocking critique engines. Structurally, it behaves as an early-stage agentic system, exhibiting recursive repair, symbolic contradiction, and layered feedback, while remaining user-controlled.
This is not frontend. This is not backend.
This is latent architecture. → Built in conversation. Structured in thought. Run in real time.
Tools built to evaluate tension, recursion, symbolic drift, composition and more.
Trained through hundreds of image case studies. Engineered with visual consequence in mind.
This isn’t AI art commentary. It’s a paradigm shift in how we see, score, and steer machine vision. The Lens steers token behavior, especially when tokens are overcharged, recursive, or clustering, to drive an image that is more complex, with deeper intent.
The LLM became runtime, multi-agent engine, scaffold system, and critic that evolved into a full-stack cognitive engine comprised of modular interpretive layers, logic scaffolds, and constraint-based recursion.

A suite of frameworks: This isn’t a style system. It’s a reasoning engine.
Built entirely inside a large language model, this five-part framework critiques how images think, how they collapse, resist, or remember, not how they look. Each can be run independently or in concert.
Sketcher Lens: critique the image and compositional failure and rebuild.
Artist’s Lens: evaluates the image poise, presence, and internal force, focuses on making better.
Marrowline: symbolic filament that interrogates meaning, offers deeper insights.
RIDP: reverse-maps prompts and images to expose the latent logic and silent structures.
Failure Suites: controlled visual ruptures, collapse prompts, degradation probes, keeps work progressing through what might collapse it.
It is not a model. It is not a filter. It is an interface for visual reasoning.
The Lens is not a style system. It’s a pressure system.
The Lens critiques visual systems from the inside, with vocabulary built not just to analyze outcomes but to steer the mechanisms and tokens producing them.
Observes system behavior
Names visual collapse
Pressurizes generative logic
And offers repair pathways that aren’t just prompt tweaks, but protocol shifts
Live intervention into clustering mechanics
The Lens watches for when token clusters create, pressuring: compositional stasis, symbolic recursion, overdetermined geometry, or gesture loops
It then subtly alters pressure to a wider set of tokens to create presence, delay, or resolution window, without needing to rewrite the prompt.
This is: Prompt conditioning steering, not rewriting. Latent-space vector repositioning. Semantically aware diffusion pressure.
Instead of “stacking synonyms,” the Lens redistributes conceptual gravity, pulling apart overused clusters and encouraging underrepresented variants to emerge.
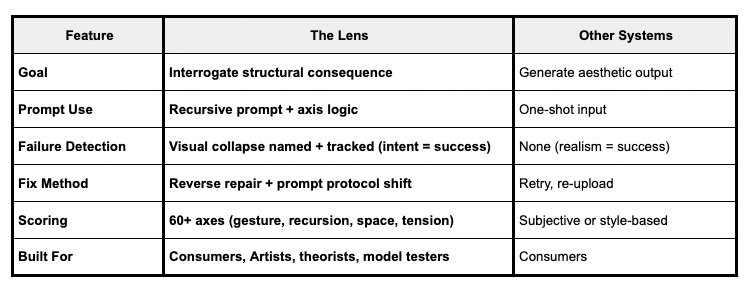
Unlike Midjourney, DALL·E, Stable Diffusion Sora, Runway, Gen-2, the Lens works by analyzing images and the prompts that formed them, tracking breakdowns, then, it reverse-engineers fixes, layer by layer, token by token, through real-time critique cycles.
Prompt interpretation linked to logic axis-aware failure detection. Other systems don’t say: “Your prompt caused spatial collapse” or “This token triggers overuse.”
They may let you change the prompt, but they don’t tell you why it failed structurally.
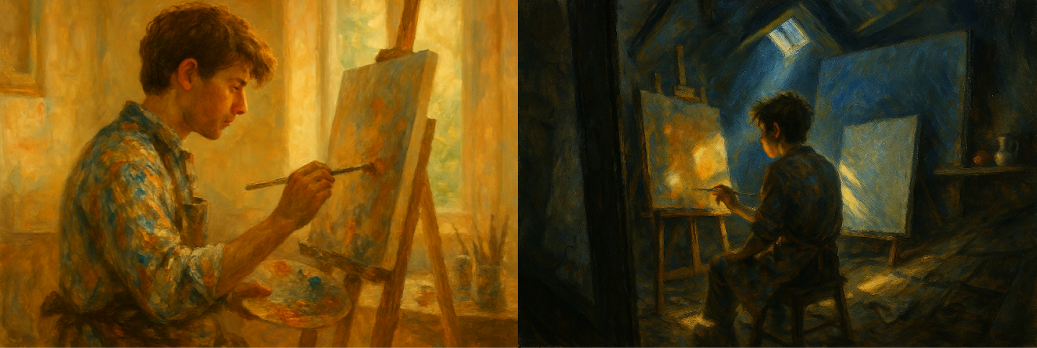
See the Teardown

See the Sketcher Work

See the Rewind
