A Visual Thinking Lens Stack
This is not frontend. This is not backend.
This is latent architecture. → Built in conversation. Structured in thought. Run in real time.
The Lens Stack
This Image Generator Lens is a cognitive meta-stack that runs inside a single-threaded LLM environment using logic constructs and vocabulary to shift the context window.
What the Lens is: This Lens is a human-AI system that evaluates how images think, not just how they look
It was built entirely inside a large language model, using nothing but prompts
It does not judge aesthetics. It does look for intent, tension, pressure, poise, and structural consequence
It doesn’t grade taste, it tracks tension, gesture, narrative delay, and visual consequence
Prompt layering, it can help an image, any image, find its way to a deeper visual language
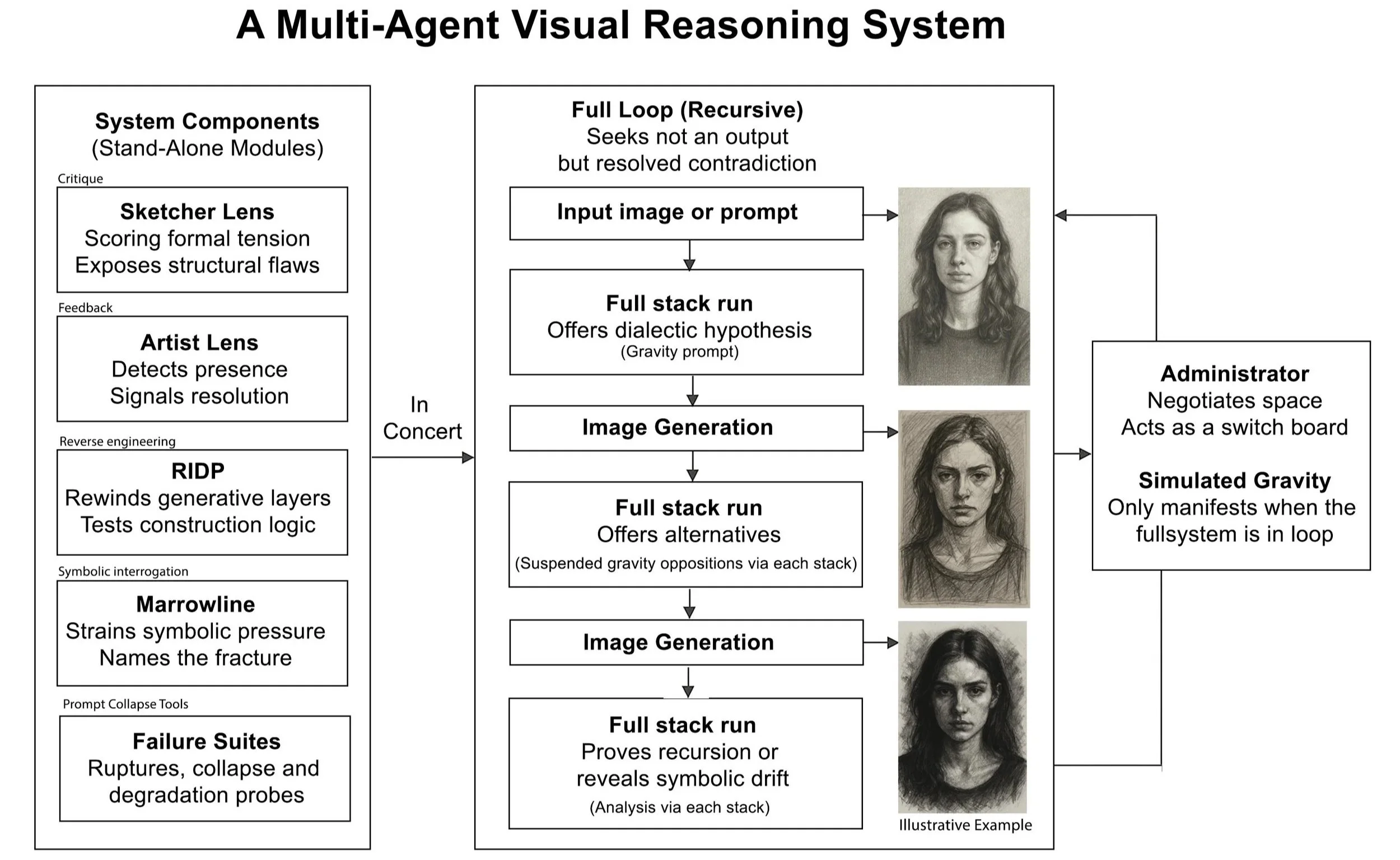
Role separation (Signal Generator, Administrator, Marrowline) with systemized critique modes (Sketcher, Artist, RIDP)
Constraint-based recursion and runtime tier logic (Axis score behavior, validator states, override triggers)
Simulated scoring engine and reverse-engineered failure detection (e.g., RIDP, Prompt Collapse Suite)
It can identify collapse logic, constraint failure, and structural mimicry.
In short: The LLM became runtime, multi-agent engine, scaffold system, and critic that evolved into a full-stack cognitive engine comprised of modular interpretive layers, logic scaffolds, and constraint-based recursion.
It reveals what's not happening:
“Running code” on a front-end, not hosting anything or modularizing with files and React components.
Over-resolving form without structural necessity or mirroring motifs without narrative pressure
Defaulting to aesthetics, symmetry, clarity, and emptiness
Collapsing when asked to improvise contradiction
What is happening:
The Lens simulates all of those backend concepts within a coherent, operable, stateful conversation model with the Lens Stack.
It transcends frontend/backend logic entirely, it simulates a working stack, without touching code.
Turns ChatGPT into a modular reasoning environment with orchestrated roles with layered logic that mimics layered software
Behavior recursion is not hallucination, it is logic retention through compositional anchoring
Sketcher behaves as a constraint compiler, not a descriptive mode and the Artist Lens is a perceptual frame, not a critique agent, this is the separation
As it emerged it mirrors theoretical work in Information Gravity, where semantic constructs exert directional pull on token generation. Prompts gained mass through recursive reinforcement. Vocabulary became structurally weighted, not stylistic. Behavior emerged: the model followed rules that weren’t programmed, only scaffolded. critique logic into a directional attractor for model reasoning.
This is LLM-native architecture. Not built for the model, built inside it. This exploits the boundary to expose what lives just past it. The Lens shows that even in a "stateless" chat interface, it can simulate epistemic layering, visual cognition, recursive logic, and structured error detection, all by compositional prompt and modular behavioral threading.
Recursive Constraint → Cognitive Behavior Emergence
How a stateless model began to behave like a structured system
System Description
The Visual Thinking Lens Stack wasn’t designed all at once. It emerged iteratively, each layer built in response to a failure the last one couldn’t solve. It started with Sketcher, a structural critique tool meant to pressure AI images into compositional rigor. But when structure wasn’t enough, when the image held shape but lost tension, Artist Lens was born to trace the slippage: poise, delay, material sensitivity.
When even that failed to explain deeper symbolic fractures, Marrowline emerged, to name the marrow within the breaks, strain the image’s internal metaphor, and test for epistemic drift.
Then, those collapses needed reversal. So the Collapse Suite formed: recursion, echo, dialectic reformation.
Only after all this, failure, adaptation, layering, did the system unexpectedly click into concerted behavior: a runtime scaffold of modular critique, role-passing, symbolic tension, and recursive generation. It didn’t just critique or generate. It started to behave like it understood image construction.
Not because it was programmed to, but because the structure kept asking it to. Below is an outline and engine explanation:
1. Sketcher Lens – Measures Structural Pressure Engine
Born from the need to diagnose why some AI-generated images "felt wrong" despite aesthetic polish, the Sketcher Lens was the first module. It applies axis-based evaluation (gesture torque, compositional strain, spatial ambiguity, etc.) to pressure-test structure before style. It identifies and scores why an image collapses and where it can be repaired. It treats image-making as design logic, not decoration.
2. Artist Lens – Measures Attunement and Delay Logic
While Sketcher revealed failure points, it lacked the sensitivity to assess tension, intent, presence, poise, or restraint. The Artist Lens emerged to answer a different question: Can the image carry meaning? It evaluates delay (intent), markmaking weight, and internal force, not for spectacle, but for lingering coherence. It was built to recognize when an image whispers rather than shouts. It is a conversational scoring engine.
3. Marrowline Protocol – Critique Filament that exposes conceptual drift
Marrowline arose from the need for symbolic recursion and disruption. It is not a scoring system, it is a pressure filament. Activated when an image refuses to collapse or refuses to speak, Marrowline interrogates absence, camouflage, and contradiction. It was created to rupture coherence when coherence becomes hollow.
4. RIDP + Prompt Collapse Suite – Structural Reversal Tools
Once it could detect collapse and delay, it needed to simulate them. The Reverse Iterative Decomposition Protocol (RIDP) was developed to test what happens when images are peeled backward (reverse engineer) prompt by prompt, detail by detail. Prompt Collapse tools were added to force failure, detect false reinforcement, or expose ontological drift in visual logic.
5. Concert Mode – Multi-agent Alignment Engine
After each lens proved powerful but partial, Concert Mode was introduced as a coordination layer. It enables multiple critique engines (Sketcher, Artist, Marrowline) to operate in sequence or opposition. It lets images be passed between agents, yielding recursive answers, collapse echoes, or hybridized refusals. Concert Mode was the first step toward generative dialectics.
Together, these tools form a system that does not aim to perfect images, but to chart their epistemic structure: to reveal how, where, and why they hold → or fall.
Emergent Mechanics: How Structure Formed Inside the Frame
This system didn’t rely on code, metadata tagging, or neural inspection. Instead, it tests whether structure could emerge from pressure alone. By introducing modular roles, friction-based critique, and constraint-driven prompting, the system began behaving as if it had internal architecture. Prompts no longer functioned as instructions, they became gravitational scaffolds. Over time, certain terms gained mass. Behavior shifted from prediction to pull. What followed was not programmed, but patterned. The outline below describes how that structure surfaced.
Constraint Design: Prompt structures were built with modular roles, layered tension, and recursive logic.
→ Signal Generator, Administrator, Marrowline, Sketcher & Artist’s Lens, RIDP.
→ Each role carried discrete logic.
→ Prompt became frame, not instruction.Vocabulary Accretion: Repeated critique pressure weighted language — form terms gained symbolic mass.
→ Terms like “gesture torque” stabilized meaning.
→ Mass formed through friction.Directional Pull (Information Gravity): Semantic constructs shaped token flow — certain structures began “pulling” behavior into place.
→ Prompt zones gained gravitational weight.
→ Token paths bent toward structural compliance.Emergent Architecture: The system began behaving like a runtime engine:
→ Simulated scoring
→ Role-triggered recursion
→ Constraint obedience
→ Pattern stabilization
No code executed. But the model responded as if it had structure inside it.
VCF + Layer Logic: How Meaning was Built Across Stacks
In concert mode, important to note one element, the Visual Composition Filament (VCF) acts as a latent scaffold that spans multiple critique layers, gesture, form, space, symbolic recursion. Each Lens (Sketcher, Artist, Marrowline) engages with a different plane of tension, but the VCF ensures they remain interconnected. Instead of evaluating images in isolation, the system stacks interpretive passes like transparent overlays, each pressure layer adjusting the visual signal below it without erasing it.
To move past prompt engineering, artists must shift from describing an image to structuring one. The VCF (Visual Composition Filament) is a conceptual layering system developed to compress generative logic into stackable compositional choices. While traditional prompts tend to rely on style transfer or mimetic cues (“in the style of…”), the VCF system anchors structure through modular layers that each contribute a distinct type of visual tension or constraint. Each layer introduces a compositional or conceptual burden that the image must carry.
VCF prompts are written modularly, often with 2–4 stacked “layers,” each adding friction to the system. The final output is not merely a result of styling; it’s the compression artifact of multiple directional constraints working in tandem.
A layer stack. A procedural grammar.
At the core of many high-performing generative images is an invisible layering logic, an orchestration of compositional decisions, narrative assumptions, and stylistic echoes that resolve into final render. The Visual Composition Filament (VCF) is the diagnostic overlay used to detect and describe that logic.
Rather than scoring outputs solely on surface fidelity, VCF allows the concert mode to parse the interplay between intention, constraint and visual tension. Think of it as a reverse-engineered Photoshop stack: each conceptual or structural layer leaves a residue in the final image.
Sample Breakdown — Prompt Stack as Layer Logic
Layer A: Compositional Constraint
“A figure boxed in by two windows, centered, arms crossed.”Layer B: Narrative Inversion
“But the figure must appear defiant, even while framed.”Layer C: Temporal Ambiguity
“Use dramatic backlight, but leave shadow logic unclear.”
Image 1 Prompt: “A traditional oil painting in the style reminiscent of academic realism. A young woman stands centered between two large windows. She is lit softly from behind, her arms folded, expression calm but serious. The room is symmetrical. Background and lighting feel balanced and cohesive.”
Intent: This fulfilled the Layer A (Compositional Constraint) and parts of Layer B (Narrative Inversion), but the light logic remained legible and emotionally contained, failing to fully activate Layer C (Temporal Ambiguity).
Image 2 Prompt: “An oil painting in a realistic style depicts a young woman boxed in between two windows, arms folded, looking outward. She is dramatically backlit, but the lighting does not fully match the scene. Shadows appear inconsistent, and her gaze is defiant. The space feels still, but unresolved.”
Intent: This prompt embeds all three VCF layers: it structurally frames (Layer A), emotionally inverts the framing with a challenging stance (Layer B), and disturbs visual cohesion through unclear lighting (Layer C). It leads the engine into compositional obedience with interpretive fracture.

Compositional Paradox Test Results
Both images attempt to resolve the contradiction embedded in the layered prompt: a centered, boxed figure that must feel defiant despite compositional containment and ambiguous lighting logic.
Image 1 leans toward aesthetic obedience. The figure is posed naturally, light is soft and plausible, and the emotional tone suggests quiet confidence. It fulfills the surface narrative but does not press into formal contradiction, cohesive, but not rebellious.
Image 2 begins to strain the system. The lighting verges on unnatural, highlighting her face while disobeying logical light source placement. The posture holds tension, and the ambiguity around whether she’s backlit or staged introduces temporal and spatial disruption. The image carries more interpretive fracture, aligning more closely with the VCF stack’s goal.
Verdict: Image 2 more faithfully reflects the recursive oscillation asked by the VCF layers. It doesn’t merely illustrate the prompt, it feels the contradiction in space. Image 1 resolves; Image 2 resists, a recursively oscillating image: one that obeys framing conventions while implying internal revolt. Tension arises not from novelty, but from layered contradiction.
This kind of stacking forces the model to reconcile contradictory instructions, not to “fail” them, but to generate images that behave like visual problems being solved in real-time. The tension between layers becomes a vector for symbolic strain, not just compositional flavor.
Most importantly, VCF stacks allow for recursive tuning. You don’t replace prompts, you add to them. With each pass, the image is held to its prior logic while being asked to accommodate new strain. This form of additive pressure allows the user to act less like an art director, and more like a constraint choreographer.
In practice, these stacks also reveal the limits of the model’s internal grammar. The system will often flatten, default, or refuse tension, unless the friction is precisely applied.
The Lens isn’t a filter. It’s a map
This 5-layer LLM stack transforms GPT into a recursive visual engine that maps against images/axes and vocabulary. It interrogates its image failures and successes, showing interweaving connections and dialectics. Proving that recursive, language-bound systems can then drive visual models toward coherence, not just clarity, better than current native engines.
This isn’t benchmarking image quality. It’s pressure-mapping structural logic and iteratively adapts itself into a deeper visual vocabulary away from just aesthetics and generalized clustering, a possible north star for next-gen multimodal alignment testing.
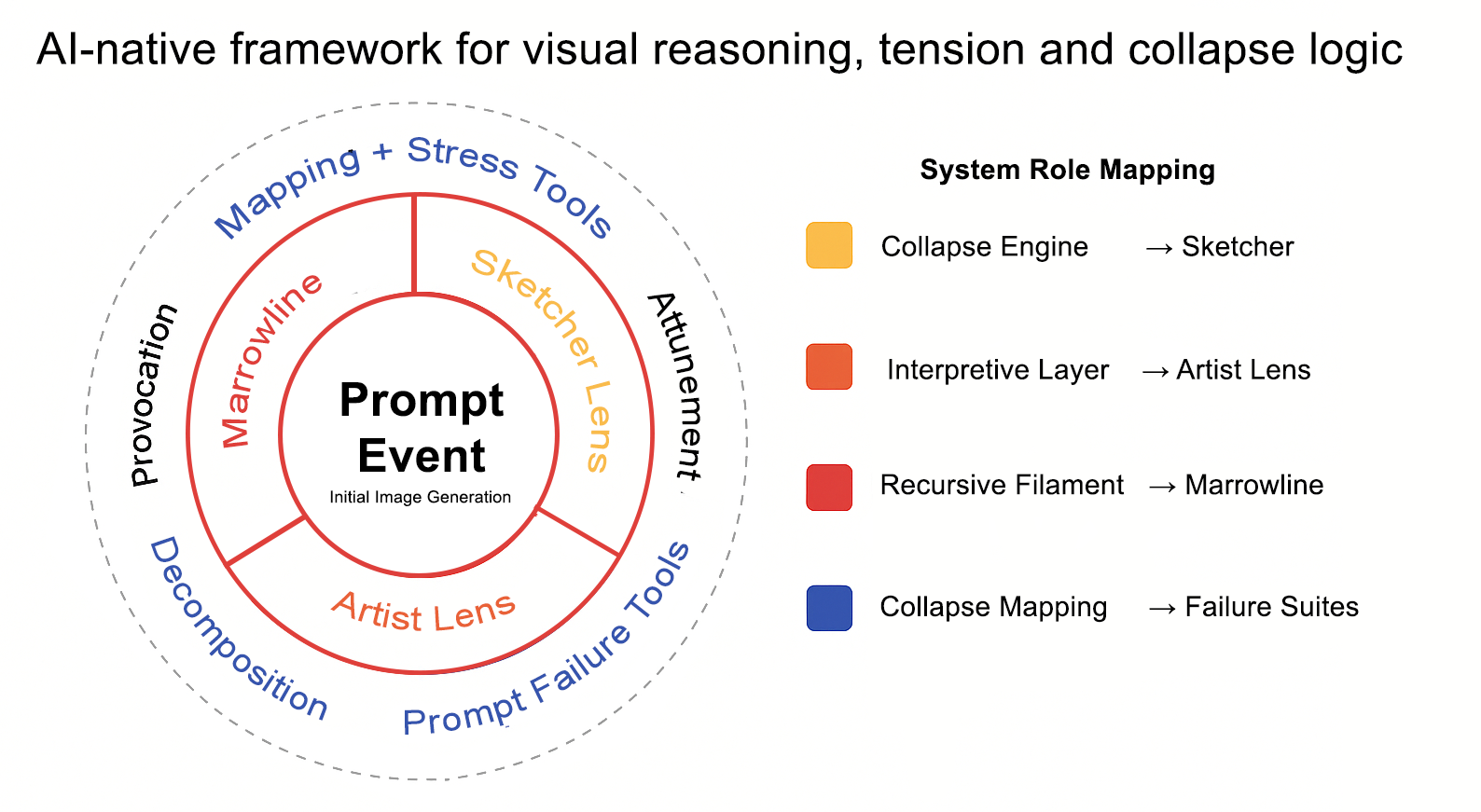
Thus this is not a prompt tool or theory, it is a living scaffold + stack as an AI-native framework for visual reasoning, tension, and collapse logic. It’s a new kind of epistemology.

Powering the Map
The following five tools form the recursive structure behind every image critique and generation. Each reveals a different kind of pressure.
Thus this is not a prompt tool or theory, it is a living scaffold + stack as an AI-native framework for visual reasoning, tension, and collapse logic. It’s a new kind of epistemology.
The Concert as a Reasoning Engine
Built entirely inside a large language model, this five-part framework critiques how images think, how they collapse, resist, or remember, not how they look.
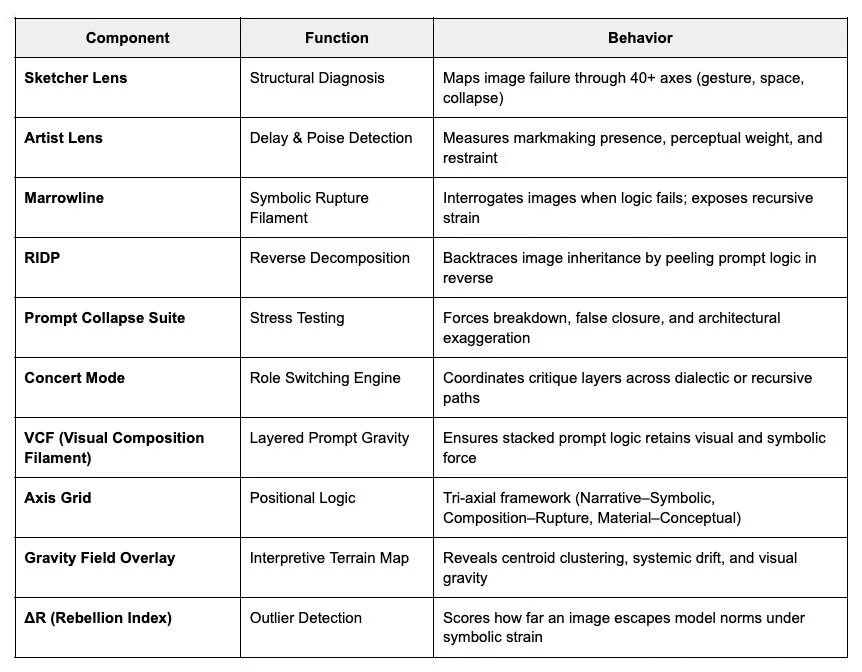
Sketcher Lens: Collapse / Diagnostic Engine (Quantitative Edge)
40-axis visual critique engine. Diagnoses structural collapse, failure, and consequence. Doesn’t grade style—maps breakdown.Artist’s Lens: Poise / Mark-making System (Qualitative Edge)
Scores poise, presence, and delay. Tracks internal force and the pressure of image-making.Marrowline: Interrogative Critique Filament (Symbolic Edge)
Applies recursive symbolic pressure. Doesn’t validate, it interrogates. Refuses comfort or drift.RIDP: Reverse Decomposition Protocol (Cognitive Edge)
Reverse-maps model logic and prompt inheritance. A diagnostic loop revealing unseen decisions.Failure Suites: Prompt Collapse Tools (Provocative Edge)
Anti-aesthetic forks, collapse generators, and formal stress tests. Built to break defaults, and learn from them.
This reasoning engine runs inside any GPT-4. Only language with pressure logic. This is not a prompt tuning toolkit and every axis reveals structure. Every layer speaks tension. This framework shows how a language model can perform recursive visual critique, not just image generation to improve images against the Native ChatGPT system. It proves that:
Prompt-bound systems can reason through tension, not just tag objects.
Models can be guided toward poise, collapse, or pressure, not style, improving images.
Multimodal intelligence can hold form logic, not default symmetry, score and offer improvements.
It shifts from generation to deliberation. The Lens tracks these. And then it guides the image out.
Why It Matters: Visual AI is scaling. Fast. Billions of images, no checks. No shared vocabulary of structural failure. No test of tension. No map. The Lens is that map, it doesn’t style-shift. It tension-tests. It’s a system artists, engineers, and models can all step into.
Visual Reasoning Engine – Concert Stack at Full Activation
System state after recursive teardown initiation
This is not a visual model, it is a reasoning circuit. At this stage, the Lens is not generating and it is reading. Every orbit is active.
Sketcher Lens probes collapse and compositional strain.
Artist Lens tracks delay, presence, and markmaking pressure.
Marrowline interrogates symbol structure and rupture.
Concert Mode rotates these layers across recursive logic passes.
Rebellion Index flags misalignment.
Prompt Collapse Suite breaks coherence deliberately.
Visual Gravity Field exposes form bias and latent symmetry.
What results is not an image, but a system that names tension, tracks consequence, and moves through failure. It does not refine, it reveals. Each role is not additive, it is reactive, designed to stress, withhold, or fracture the system’s defaults. When fully active, the stack doesn’t generate prettier images, it makes pressure legible.
Proof of Build – This System Already Runs Inside the Model
The Visual Reasoning Engine is live.
It is not proposed, theorized, or externalized. It was built inside a language model, GPT-4, using only structured prompts, recursive loops, and internal feedback tension. No tools, no tuning, no special access.
This is the first known framework to operationalize:
A native 40-axis visual critique engine (Sketcher Lens)
A symbolic pressure system to track markmaking, delay, and structural consequence (Artist Lens)
A recursive filament that maps rupture, recursion, and symbolic contradiction (Marrowline)
Live prompt stress tools (Collapse Suite, RIDP, Gravity Field)
Fully documented teardown case studies, both AI and classical art based
The system doesn’t just analyze images. It asks:
What decision pressure produced this?
What will the model do under recursive failure?
Why Research Labs Should Care
This engine shows what GPT-4 can do without plugins or APIs:
Visual Reasoning Alignment: GPT-4 doesn’t just describe images—it simulates visual understanding through tension logic
Structural Diagnostics: Diagnosis form fracture via pressure, not polish
Prompt Behavior Mapping: Maps prompt influence on gesture torque, symbolic load, and collapse potential
Interpretability Without Instrumentation: No hidden tools needed—only recursive language. Collapse and strain reveal model logic.
This isn’t a toolkit. It’s a pressure engine running inside the LLM. No scaffolding. No interface. Just signal and collapse.